판다스의 apply() 메서드의 기본 문법은 다음과 같다.
apply() 메서드는 pandas 객체에 열 혹은 행에 대해 함수를 적용하게 해주는 메서드이다.
DataFrame.apply(func,axis=0,raw=False,result_type=None,args=(),**kwds)
*func: 이 입력변수는 pandas 객체의 열이나 행에 적용할 함수를 입력받는다.
*axis:함수를 적용할 축을 지정한다.
-Series에 적용할 경우에는 axis를 따로 지정해주지 않는다.
-0 or 'index'
example) DataFrame.apply(func,axis=0), DataFrame.apply(func,axis='index')
:함수를 각 열(columns)에 따라 적용한다.
-1 or 'index'
example) 위와 동일
:함수를 각 행(row)에 따라 적용한다.
*agrs: func에 입력되는 위치 입력변수를 입력받는다. 즉, iterable한 자료형을 입력받는다. (list,tuple등)
*kwds: func에 입력되는 키워드 입력변수를 입력받는다. ->키워드에 입력될 입력값의 mapping을 입력받는다.
우선 데이터프레임을 간단하게 만들어보자.
import pandas as pd
import numpy as np
df=pd.DataFrame([[4,9]]*3,columns=['A','B'])
df

df.apply(np.sqrt)
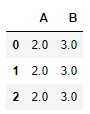
위 코드처럼 단순히 apply()메서드에 func를 지정하면 각 Series로 처리가 된다. 즉 Series에서도 셀 당 처리를 해준다.
df.apply(np.sum,axis=0)
A 12
B 27
dtype: int64axis=0으로 지정해 주었을 경우, 위 정의처럼 각 column에 따라 적용한다.
그러므로, A 와 B column에 대하여 전체 합을 처리해준다.
df.apply(np.sum,axis=1)
0 13
1 13
2 13
dtype: int64axis=1로 지정해 주었을 경우, 위 정의처럼 각 row에 따라 적용한다.
그러므로 index별로 전체 합을 처리해준다.
lambda 함수를 적용한 응용 apply()
다음 예를 확인해보자.
df.apply(lambda x: [1,2],axis=1)
0 [1, 2]
1 [1, 2]
2 [1, 2]
dtype: object위 코드를 살펴보면 lambda함수를 사용해 [1,2] 리스트 형식을 axis=1이라는 조건을 통해 각 row에 적용시킨다.
그러면 위 결과와 같이 Series의 결과를 얻게 된다.
df.apply(lambda x:[1,2],axis=1,result_type='expand')
위 코드를 살펴보면 lambda함수를 사용해 [1,2]의 리스트를, axis=1이라는 조건을 통해 각 row에 적용 시키는데, 위 예제와 다른점은 result_type='expand' 조건을 추가 적용했다.
result_type = 'expand'를 전달하면 목록과 유사한 결과가 데이터 프레임의 열로 확장된다.
그러므로 column_name은 0과 1(default)로 지정되고 각 data만 expand(확장)된것을 확인할 수 있다.
df.apply(lambda x:pd.Series([1,2],index=['foo','bar']),axis=1)
위 코드를 살펴보면 lambda함수를 통해 각 [1,2]로 되어있는 시리즈를 생성하고, index=['foo','bar']을 지정해준다. 추가로 axis=1을 지정해 줌으로써 각 row에 적용시키는데 위와 같은 결과를 얻을 수 있다.
df.apply(lambda x:[1,2],axis=1,result_type='broadcast')
위 코드를 살펴보면 lambda 함수를 통해 리스트형식인 [1,2]를, axis=1을 지정해줌으로써, 각 row에 삽입해준다.
추가로 result_type = 'broadcast'를 전달하면 함수가 목록 형이든 스칼라이든 상관없이 동일한 모양 결과를 보장하고 축을 따라 브로드 캐스트한다. 결과 열 이름은 원본이된다.
*result_type이란 앞서 조건이라고 말했지만 명확히 정의하자면 매개변수(parameter)이다.
{'expand','reduce','broadcast','None'} 종류가 있으며 axis=1 즉, row에만 적용 가능하다.
'Data analysis > Pandas' 카테고리의 다른 글
| [Pandas] DataFrame (0) | 2021.01.15 |
|---|---|
| [Pandas] Series (0) | 2021.01.15 |
| [Pandas] DataFrame 특정 칼럼 혹은 인덱스 선택 (0) | 2021.01.13 |
| [Pandas] DataFrame(개념) (0) | 2021.01.13 |



