Published by the IEEE Computer Society
[Korea University]
Kang-Min Kim Jun-Hyung Park Woo-Jong Ryu Sang-Keun Lee
위 논문은 고려대학교 논문을 발췌해 리뷰를 한것이다.
[논문 발췌]라고 적힌 문장들은 본인이 읽으며 중요하다고 생각하는 문장들을 적어 놓은 것이다.
Intro.
As the usage..
스마트폰 사용량이 증가함에 따라 WhatsApp,Viber,Snapchat 등 많은 채팅어플리케이션이 사용된다.
또한, 자주 사진을 문자만큼이나 많이 공유한다. 수치로는 매일 45억개의 사진을, 55억개의 문자를 보내는데 이는 Whatsapp 플랫폼에서만의 기준이다.
최근들어 Intelligent assistant 기술이 스마트폰 메시지 어플에 많이 접목된다. 예를들면, google allo, google assistant등.. 이것때문에 대화를 더욱 편하고 풍부하게 사용할 수 있게 되었다.
Figure 1. Scenario of meChat

대부분의 Intelligent assistant는 대화영 인터페이서 서버쪽에 자리잡고 있다. 그 말인 즉슨, 서버는 사진을 분석하고 수집한다는 말인데 이는 정보 보안에 민감하다.
[논문 원문 발췌]
Thus, it may lead to privacy leaks.
즉, 이는 정보 유출의 가능성도 있다.
*흔히 2020 빅데이터 컨퍼런스에서도 가장 중요한 주제 중 하나는 데이터가 많아지면 많아질수록 데이터에 대한 보안이 가장 중요하다 하였다. 이에 대한 해결법으로 블록체인을 얘기하기도...
이 논문에서는 스마트폰 내부의 on-device형식인 personal assistant를 이용한 meChat을 이야기한다.
meChat의 세가지 기능.
-사용자 간의 대화 문맥을 이해한다.
-사진의 의미를 수집한다.
-마지막으로 대화 문맥과 관련 있는 의미를 찾아내어 in-device형식으로 사진을 찾는다.
주목해야 할 점은, meChat은 conversation text를 semantic space로 프로젝트 한다 이와 동시에 photos를 semantic space로 프로젝트 한다.
[논문 원문 발췌]
Thus, meChat is able to model, understant and compare different modalities on top of a single unified semantic space.
흥미로운 점은 앞서 언급된 것처럼 meChat은 on-device text intelligence형식이므로, intelligent assistants 를 독립형 방식으로 수행한다.
[논문 원문 발췌]
Thus, meChat works in a privacy-protecting manner without sending out any in-device photos out-side. It does not suffer from any communication latency to the external server.
-meChat SCENARIO
Figure 1. 을 살펴보면, meChat이 어떤 방식으로 사용자를 도우는지 알 수 있다. 대략 논문을 간단하게 표현해 보면, Ella는 친구와 대화를 하며, 저녁을 먹자 하고, 이에 대해 @mechat을 외치며 사진을 보내달라한다. 이에 meChat은 앞서 말한 in-device형식으로 스마트폰 내부 저장소에서 안전하게 사진을 가져온다. 여러개의 매칭된 사진을 나열시켜 보여주고 이에 사용자는 원하는 사진을 선택한다.
[논문 원문 발췌]
Notably, meChat intelligently searches indevice photos against the semantics of conversations on smartphones, whereas most existing intelligent assistants work it on their servers. Thus, meChat does not send in-device photos outside or suffer from communication latency to the servers.
-METHODOLOGY
meChat을 구상하며, ODP(Open Directory Project) 기반으로 의미적 접근을 하였다.
의미적 접근(sementic approach)는 의미적 분류(semantic classification) 과 의미적 순위법(semantic ranking)으로 구성되 어있고 훈련은 ODP를 통해서 훈련되어졌다.
ODP를 좀더 설명하자면 최대 15레벨의 웹 디렉토리, 360만 개 이상의 웹페이지가 백만개의 카테고리로 구성되어있는
고품질 및 대규모 분류체계 사이트이다.
Conversation Classification
사용자를 이해하는 것이 meChat의 본질적인 일이다. 이에 진행중인 대화가 사용자를 이해하는데 아주 중요하다는것에 중점을 두어 연구했다.
[논문 발췌]
We interpret the classified ODP categories as conversation contexts.
좀더 구체적으로 보자면, vector space model을 기반으로 한 term vector로써 대화속에 텍스트들을 표현한다.
이후 Conversation Vector와 ODP categories vector들 간에 Cosine similarity를 측정한다. 분류에서, 각각의 ODP category는 vector space model에 기반한 그 각각의 category의 의미를 표현하는 vector을 갖고있다.
이후 , meChat은 몇 가지 계산된 Cosine Similarity를 기반으로한 관련성 높은 ODP categories를 얻는다.
Photo Classification
in-device photos의 의미를 찾기 위해 meChat은 ODP categories로 사진들을 분류함으로써 ODP semantic space에 사진을 project한다.
*여기서 project는 같은 의미로 벡터사영이라고 해도 이해해도 괜찮을 것 같다.
결과적으로, in-device의 object와 place 정보 두가지를 활용한다. meChat은 Tensorflow Lite에 의해 제공된 MobileNets를 사용한 사진속 object를 인식한다.
[논문 발췌]
In particular, meChat uses venue categories as place information obtained from Foursquare APIs. Subsequently, meChat puts both the recognized objects and the obtained venue categories together into a single contextual text, which are then classified into a few highly related ODP categories.
위 과정이 meChat이 ODP category로 분류하는 과정의 세심한 내용이며 본인도 중요하다 생각해 발췌한다.
[논문 발췌]
Notably, meChat is able to model, understand, and compare conversation text and in-device photos on top of a single ODP semantic space, by transforming both into ODP categories. This is one-of-a-kind in the literature.
주목할 점은, meChat은 모델링하고,이해하며 대화 텍스트와 기기 내 비교 단일 ODP semantic 공간위에 있는 사진 둘다 ODP 범주로 변환한다. 이는 문학에서 유일무이하다.
Photo Ranking
meChat은 in-device에서 대화 문맥과 사진을 match한다.
[논문 발췌]
To this end, it utilizes GraphScore to effectively measure the semantic similarity between the conversation and in-device photos.
*특히 GraphScore는 ODP taxonomy로부터 얻은 Similarity graph에 대한 wPPR(weighted Personalized Page Rank) function을 computing함으로써 sementic similarity를 얻는다.
[Definition of GraphScore]
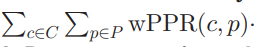
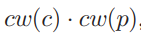
where) C and P are a set of top-k classified ODP categories of conversation and in-device photos, respectively.
wPPR(c,p)는 c와 p의 semantic relevance이고, 반면에 cw(c)와 cw(p)는 각 c와 p의 classification score 이다.
[논문 발췌]
Finally, it obtains a ranked list of semantically relevant in-device photos to the given conversation.
Prototype of meChat
meChat을 테스트해보기 위해 사용한 스마트폰은
-Samsung Galaxy S7 with Android 6.0.1 Marshmallow
-LG Nexus 5X with Android 8.1 Oreo
특히, tiny text intelligence라 불리는 on-device text intelligence를 활용했다. 이를 'me' 라고 부른다.
이것의 지식 기반은 잘 구성된 전체 892개의 category를 가진 ODP taxonomy로 만들어졌다.
ODP knowledge-base의 top에서 'me'는 semantic classification과 semantic ranking을 지원한다.
SQLite를 사용함으로써, 38.9MB 되는 크기의 'me'를 smartphone에 넣는다.
추가적으로 meChat의 실행가능성을 시험해보기 위해 두개의 스마트폰에 messaging application을 설치한다.
*실제 구현을 보고싶다면 다음 링크를 확인해보자. https://youtu.be/ 4BzwMrhW8Ac.
위 Figure 2는 meChat의 architecture을 보여준다.
'me'와 context analyzer, photo analyzer, photo searcher을 포함한 세가지 software module을 포함하고 있다.
context analyzer과 photo analyzer은 on-going 대화와 in-device 사진들을 각각 분류한다.
photo searcher는 on-going 대화와 사진들 사이의 semantic similarity을 기반으로 in-devices 사진에 순위를 매긴다.
[논문 발췌]
In me Chat, the photo analyzer works offline(i.e., when taking photos), while the context analyzer and photo searcher work online(i.e., when calling meChat)
meChat에서, photo analyzer는 offline으로 수행하는(사진을 찍을때) 반면 context analyzer과 photo searcher은 온라인으로 수행한다(meChat을 부를때).
합리적인 정확성 뿐만아니라 스마트폰에 어울리는 적당한 사이즈를 고려하여 모델을 선택했는데 photo analyzer에서 기기 내 사진의 GPS에 해당하는 장소 category를 얻기 위해 Place API of Foursquare을 사용했고, in-device 사진들의 objects를 인식하기 위해 'MobileNet_v1_1.0_224_quant'이라는 computer vision model을 활용했다.
*Place API of Four Square http://(https://developer.foursquare.com/places-api/)
*MobileNet_v1_1.0_224_quant (https://github.com/ tensorflow/models/blob/master/research/slim/ nets/mobilenet_v1.md/)
Performance Evaluation
[논문 발췌]
The goal of our experiments is to examine the efficacy of meChat in daily life conversations.
이 실험의 목표는 일상 대화에서의 meChat의 efficacy이다.
*세명의 졸업생으로부터 211개의 위치가 저장되어있는 in-device 사진들을 수집.
* 이전 작업으로부터 사용한 33개의 scenario-based 기기 내 사용 데이터를 빌린다.
* 33개의 scenario 중 오직 16개의 sms text scenario를 대화로서 가져왔다 .이유는 남은 17개의 대화는 수집한 사진과 연관성이 없기 때문!
*이에 수집한 사진과 연관이 있는 다른 시나리오에 대한 17개의 대화 데이터를 추가적으로 구축하였다.
*마침내, 평균 136 term 길이의 33개 대화 데이터를 얻었다.
Conversation and Photo Classification
-Conversation classification의 성능 테스트
*대화가 주어지면 상위 5개 ODP 분류 카테고리와 관련하여 문장을 추론한다.
*그 다음, 세가지 다른 크기로 각각 ODP 카테고리를 label을 부여하는데 관계있고, 어느정도 관계있고, 관계없는 것으로 처리한다.
*k정확도와 관련하여 성능을 측정한다. (이 성능 metric은 추천 알고리즘 분야에서 가장 많이 쓰이는 것)
위 table을 보면 meChat은 conversation classification에서 준수한 성능을 보여주고 있다.
-classifuing in-device photos
*이와 관련하여 성능에 대한 세가지 접근을 비교했다.
1) 앞서 제안된 GPS와 일치하는 장소 정보만을 분류하는 접근. (denoted as meChat pla)
2) 사진객체만을 단지 분류하는 접근 (denoted as meChat obj)
3) 위치정보와 객체 두가지를 넣음으로써 생성된 문맥 텍스트를 분류하는 접근. (denoted as meChat pla+obj)
*여기서 meChat(pla)가 가장 나쁜 성능을 보여줬다. 이유는 대부분 in-device photos는 더 낮은 위치 정보에 대한 정확도를 제공해주는 도심지역에서 찍혔기 때문이다.
*또한, 각 장소에서 얻어진 장소 category는 일반적으로 classification 성능을 낮게하는 결과를 만든 적어도 하나의 관련없는 category를 포함한다.
*meChat(obj)도 여전히 낮은 성능을 보여준다. 경험적으로 MobileNets의 낮은 객체 인식성능으로부터 이 결과가 나온건데 이는 5가지 정확도분석과 관련하여 거의 18퍼센트정도 낮게 측정되었다.
*주목해야할점은, meChat(pla+obj)는 가자 좋은 성능을 보여주었다. 특히, 정확성과 관련하여 meChat(pla)보다는 58.5%, meChat(obj) 보다는 13.9% 이상의 향상을 보여주었다.
[논문 발췌]
The above experimental results clearly show that it is effective to project both place information and objects of photos on an ODP semantic space with respect to enriching the semantics of photos.
하지만, 전반적인 현실의 in-device photos분류의 저조한 성능은 다양한 관점에서 개선할 방법이 여전히 많다는걸 의미한다.
-Photo Ranking 성능 테스트
대화와 관련하여 정확성에 대한 k 와 MRR(mean reciprocal rank)를 이용해 in-device photo ranking을 평가하였다.
오직 top-ranked in-device photo에만 집중을 하였다. 왜냐하면 스마트폰은 사진을 보여주기에는 너무나 제한적인 화면이기 때문.
*기본적으로, syntactic 접근을 사용하였다. 이 접근은 대화와 in-device photo로부터 추출한 정보사이의 cosine similarity를 기반으로 하였다.
*위 사진을 보면, meChat(pla+obj)는 k와 MRR정확성에 대한 접근에서 다른 것보다 월등한 성능을 보여줬다.
*구체적으로, meChat(pla+obj)의 성능은 세가지 추천된 사진들에 대해 적어도 하나는 공유되어진다는 것이다.
*위 깊이 분석을 통해서, 다음과 같은 observations를 만들었다.
[논문 발췌]
1) Utilizing both place information and objects of photos is much more effective than utilizing either of them alone. 2) Each semantic approach (i.e., meChat) achieves better performance than corresponding syntactic approach (i.e., Keyword).
1)place information과 photos의 objects 두개를 활용하는 것이 각각을 따로 사용하는것보다 더 나은 성능을 보여준다.
2)각각의 semantic approach는 일치하는 syntactic approach보다 더 나은 성능을 보여준다.
-System 성능 테스트
이를 시험하기에 앞서 Samsung Galaxy S7 smartphone 의 런타임과 에너지 소비를 먼저 측정하였다.
*우선 런타임과 관련하여 클라우드 기반 text classification 과 meChat을 비교했다.
위 table3와 같이 meChat이 IBM보다 더 나은 성능을 보여준다.
*런타임의 차이점은 mobile broadband 환경에 따라 증가한다.
*Monsoon power meter을 사용한 meChat의 에너지 소비를 추가로 측정하였다.
*이는 음악을 듣는것 에너지 소비와 동일하다.
*이후에, meChat과 Microsoft cognitive service의 image classification을 사용한 Mobile-Nets을 비교했다.
*클라우드 기반 Ms categorize는 그들의 86가지 category를 기반으로한 image categorizing을한다. 이에 대해 사진 한장에 MobileNets은 0.160s 가 걸리고 반면 클라우드 기반 MS는 7.338걸린다.
[논문 발췌]
The above-mentioned experimental results quantitatively indicate that privacy and latency benefit greatly from ondevice intelligence.
CONCLUSION
외부 서버에 의존하지 않은 스스로 작업을 할 수 있는 meChat은 사용자들에게 in-device photos와 관련하여 의미적인 공유를 도와줄 수 있다.
외부 서버를 사용할 시에는 보안에 대해 가장 민감하기에 위 방법은 아주 참신하다.
[논문 발췌]
We believe meChat is oneof-a-kind personal assistant in that it works in a privacy-protecting manner with low perceived latency and energy consumption
meChat의 고유한 기능은 model,understand를 가능하게 해주고 통합된 ODP sematic spacec에서 in-device와 photos에 대한 대화 문맥을 비교할 수 있게 해준다.
2021-01-18~ 2021-01-21
meChat: In-Device Personal Assistant for Conversational Photo Sharing.
논문 해석 및 리뷰 완료.
-불굴의관돌이