Transformer는 2017년 구글이 발표한 논문인 'Attention is all you need'에서 나온 모델이다.
기존의 seq2seq 구조인 encoder-decoder를 따르면서도 논문의 이름처럼 어텐션 기법만으로 구현한 모델이다.
이 모델은 RNN을 사용하지 않고, 단순히 encoder-decoder 구조를 설계하였음에도 RNN보다 성능이 우수하다고 나왔다.
원논문은 다음 링크를 타고 확인해보자.
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
기존의 seq2seq 모델의 한계
트래느포머에 대해 알아보기 전에 기존의 seq2seq모델을 먼저 알아보자. 기존 seq2seq모델은 인코더-디코더 구조로 구성되어 있다.
인코더가 하는 일: input sequence를 하나의 벡터로 압축
디코더가 하는 일: 이 벡터 표현을 통해 output sequence를 만들어낸다.
단점: 인코더가 하나의 input sequence를 하나의 벡터로 압축하는 과정에서 input sequence의 정보가 일부 손실된다.
위 단점을 보완하기 위해 어텐션 기법이 사용되었다.
그렇다면 RNN을 보정하기 위한 용도로 사용하지 않고, 직접 어텐션으로 인코더와 디코더를 사용한다면 어떻게 될까
Transformer의 Main Hyperparameter
트랜스포머의 하이퍼파라미터를 정의해보자. 각 하이퍼파라미터의 의미에 대해서는 후에 설명하고, 간단하게만 이해해보자. 아래 정의되는 수치값은 트랜스포머를 제안한 논문에 기재된 수치값이다. 그러나 사용자가 모델 설계시 임의로 변경가능한 값이다.
d(model) =512
트랜스포머의 인코더와 디코더에서 정해진 입력과 출력의 크기를 의미한다. 임베딩 벡터의 차원 또한 d(model)이며, 각 인코더와 디코더가 다음 층의 인코더와 디코더로 값을 보낼 때에도 이 차원을 유지한다.
num_layers=6
트랜스포머에서 하나의 인코더와 디코더를 층으로 생각하였을 때, 트랜스포머 모델에서 인코더와 디코더가 총 몇 층으로 구성되었는지를 의미한다.
num_heads=8
트랜스포머에서는 어텐션을 사용할 때, 1번 하는 것 보다 여러 개로 분할해서 병렬로 어텐션을 수행하고 결과값을 다시 하나로 합치는 방식을 선택했다. 이때의 병렬 개수를 의미한다.
d(ff)=2048
트랜스포머 내부에는 feed forward neural network가 존재한다. 이때 hiddenlayer의 크기를 의미한다.
*feed forward neural network의 input layer, output layer의 크기는 d(model)이다.
트랜스포머(Transformer)

트랜스포머는 RNN을 사용하지 않지만 기존의 seq2seq처럼 인코더에서 입력 시퀀스를 입력받고, 디코더에서 출력 시퀀스를 출력하는 인코더-디코더 구조를 유지한다.
하지만 트랜스포머와 seq2seq의 차이점은 encoder, decoder 단위가 N개 존재 할 수 있다는 것이다.
즉, 이전 seq2seq 구조에서는 encoder,decoder에서 각각 하나의 RNN이 t개의 시점(time_step)을 가지는 구조였다면, 이번에는 encoder,decoder단위가 N개로 구성되는 구조이다.
논문에서는 encoder,decoder 개수를 6개씩 사용했다.

위 그림은 encoder,decoder가 6개씩 존재하는 트랜스포머 구조이다.

위 그림은 encoder로부터 정보를 전달받아 출력 결과를 만들어내는 트랜스포머 구조를 보여준다. decoder는 seq2seq구조처럼 시작 심볼<sos>를 입력으로 받아 종료 심볼<eos>가 나올 때까지 연산을 진행한다.
RNN은 사용되지 않지만 여전히 encoder-decoder구조는 유지되고 있음을 보여준다.
그렇다면 이제 전체적인 큰 흐름은 확인했으니 내부 구조를 확인해보자.
포지셔널 인코딩(Positional Encoding)
내부를 이해하기에 앞서, 트랜스포머 입력을 알아보자. RNN이 자연어 처리에 유용했던 이유는 단어 위치에 따라 순차적으로 입력받아서 처리하는 RNN의 특성으로 인해 각 단어의 위치정보를 가질 수 있었다.
이와는 다르게 트랜스포머는 단어 입력을 순차적으로 받는 방식이 아니므로, 단어의 위치 정보를 다른 방식으로 알려줄 필요가 있다. 이 정보를 얻기 위해 각 단어의 임베딩 벡터에 위치 정보들을 더하여 모델의 입력으로 사용하는데, 이를 포지셔널 인코딩(Positional Encoding)이라고 한다.

위 그림은 입력으로 사용되는 임베딩 벡터들이 트랜스포머의 입력으로 사용되기 전에 포지셔널 인코딩 값이 더해지는 것을 보여준다.

위 그림이 실제 임베딩 벡터가 입력으로 사용되기 전에 포지셔널 인코딩값이 더해지는 과정을 시각화한 그림이다.
포지셔널 인코딩 값들은 어떤 값이기에 위치 정보를 반영해준다는 것일까? 다음 두가지 함수를 보자.

위 sin,cos함수는 위아래로 순환하여 요동친다. 즉, 이 함수를 이용해 임베딩벡터에 더해줌으로써, 단어의 순서 정보를 더하여준다.
pos는 입력 문장에서의 임베딩 벡터의 위치를 나타내며, i는 임베딩 벡터 내의 차원의 인덱스를 의미한다. 각 차원의 인덱스가 짝수인 경우에는 sin함수의 값을, 홀수인 경우에는 cos함수의 값을 사용한다.
위 식에서 d(model)은 트랜스포머의 모든 층의 출력 차원을 의미하는 하이퍼파라미터이다. 위에서 단어의 정의를 언급하였듯이 계속 나오게 될것이므로 기억해두자.
위와 같은 포지셔널 인코딩 방법을 사용하면 순서 정보가 보존되는데, 예를 들어 각 임베딩 벡터에 포지셔널 인코딩 값을 더하면 같은 단어라 하더라도 문장 내의 위치에 따라서 트랜스포머의 입력으로 들어가는 임베딩 벡터의 값이 달라진다.
코드로 살펴보자.
class PositionalEncoding(tf.keras.layers.Layer):
def __init__(self,position,d_model):
super(PositionalEncoding,self).__init__()
self.pos_encoding=self.positional_encoding(position,d_model)
def get_angles(self,position,i,d_model):
angles=1/tf.pow(10000,(2*(i//2))/tf.cast(d_model,tf.float32))
return position*angles
def positional_encoding(self,position,d_model):
angle_rads=self.get_angles(position=tf.range(position,dtype=tf.float32)[:,tf.newaxis],i=tf.range(d_model,dtype=tf.float32)[tf.newaxis,:],d_model=d_model)
#배열의 짝수 인덱스(2i) 사인함수
sines=tf.math.sin(angle_rads[:,0::2])
#배열의 홀수 인덱스(2i+1) 코사인함수
cosines=tf.math.cos(angle_rads[:,1::2])
angle_rads=np.zeros(angle_rads.shape)
angle_rads[:,0::2]=sines
angle_rads[:,1::2]=cosines
pos_encoding=tf.constant(angle_rads)
pos_encoding=pos_encoding[tf.newaxis,...]
print(pos_encoding.shape)
return tf.cast(pos_encoding,tf.float32)
def call(self,inputs):
return inputs+self.pos_encoding[:,:tf.shape(inputs)[1],:]위 클래스를 이용해 포지셔널인코딩을 정리하였다. 여기서 가장 주의깊게 봐야할 부분은 짝수,홀수일때 어떤 함수를 사용하는가이다.
sample_pos_encoding=PositionalEncoding(50,128)
plt.pcolormesh(sample_pos_encoding.pos_encoding.numpy()[0],cmap='RdBu')
plt.xlabel('Depth')
plt.xlim((0,128))
plt.ylabel('Position')
plt.colorbar()
plt.show()50x128의 크기를 가진 포지셔널 인코딩 행렬을 시각화하여 어떤 형태를 가지는지 확인해보자.
(1, 50, 128)

단어가 50개이면서, 각 단어가 128차원의 임베딩 벡터를 가질 때 사용할 수 있는 행렬이다. 좀 더 쉽게 설명하면, '관돌'이라는 단어가 가질 수 있는 고유 숫자(벡터)는 128개라고 이해해도 괜찮다고 본다.
어텐션(Attention)
트랜스포머에서 사용되는 3가지 어텐션에 대해 간단하게 정리하자.

Self-Attention은 인코더에서 이루어지는 반면에 Masked Decoder Self-Attention , Encoder-Decoder Attention은 디코더에서 이루어진다. 셀프 어텐션은 본질적으로 Query,Key,Value가 동일한 경우를 말한다. 반면, 세번째 그림 인코더-디코드 어텐션에서는 Query가 디코더의 벡터인 반면에 Key,Value가 인코더의 벡터이므로 셀프 어텐션이라 불리지 않는다.
*Query,Key 등이 같다는 것은 벡터의 값이 같다는 것이 아닌, 벡터의 출처가 같다는 의미이다.

전체적인 트랜스포머의 구조이다. 여기서 Multi-head라고 추가가 되었는데, 이는 간단하게 병렬수행으로 생각해두자. 뒤에 다시 언급할 것이다.
인코더(Encoder)

앞서 말했듯이 트랜스포머는 하이퍼파라미터인 num_layers 개수의 인코더 층을 쌓는다. 총 6개의 인코더 층을 사용하였다.
인코더를 하나의 층이라는 개념으로 생각해본다면, 그 층은 크게 총 2개의 sublayer로 나뉜다. 이 sublayer는 셀프 어텐션과 피드 포워드 신경망이다. 위 그림에서 FFNN과 Self-Attention이라고 적혔는데, 멀티 해드 어텐션은 셀프 어텐션을 병렬적으로 사용한다는 의미고, Position-wise FFNN은 일반적인 FFNN이다.
우선 셀프 어텐션에 대해서 먼저 이해해보자.
Self-Attention
트랜스포머에서는 셀프 어텐션이라는 어텐션 기법이 등장하는데, 어텐션 기법에 대해서는 추후 다루도록 하겠다.
1) 셀프 어텐션의 의미와 이점
어텐션 함수는 주어진 query에 대해서 모든 key와의 유사도를 각각 구한다. 그리고 구해낸 이 유사도를 가중치로 하여 키와 맵핑되어있는 각각의 value에 반영해준다. 그 후, 유사도가 반영된 value를 모두 가중합하여 return 한다.

셀프 어텐션에 대한 대표적인 효과를 이해해보자.

위 그림에서 'The animal didn't cross the street because it was too tired'라는 글을 해석해보면 '그 동물은 그것이 너무 힘들어서 길을 건너지 않았다' 이다. 여기서 it 이 의미하는 건 무엇일까? 'street' 혹은 'animal'중 하나일 것이다. 이 셀프 어텐션을 이용하면 결국 animal에 더 연관되어 있다는 즉, 확률이 높다는 것을 찾아내 준다.
이제 트랜스포머에서의 셀프 어텐션의 동작 메커니즘을 알아보자.
2) Q,K,V 벡터 얻기
셀프 어텐션은 입력 문장의 단어 벡터들을 가지고 수행한다고 하였는데, 사실 어텐션은 인코더의 초기 입력인 d(model)의 차원을 가지는 단어 벡터들을 사용하여 셀프 어텐션을 수행하는 것이 아닌, 각 단어의 벡터들로부터 Q,K,V벡터를 얻는 작업을 거친다.
이때 Q,K,V벡터들은 초기 입력인 d(model)의 차원을 가지는 단어 벡터들보다 더 작은 차원을 가지는데, 논문에서는 d(model)=512의 차원을 가졌던 각 단어 벡터들을 64의 차원을 갖는 Q,K,V벡터로 변환하였다.
여기서, 64라는 값은 트랜스포머의 또 다른 하이퍼파라미터인 num_heads로 인해 결정된다. 트랜스포머는 d(model_을 num_heads로 나누 값을 각 Q,K,V벡터의 차원으로 결정한다. 논문에서는 num_heads를 8로 설정하였다.

기존 벡터로부터 더 작은 벡터는 가중치 행렬을 곱하므로써 완성된다.
3) Scaled dot-product Attention
Q,K,V 벡터를 얻었다면 기존 어텐션 메커니즘과 동일하다. 각 Q벡터는 모든 K벡터에 대해서 어텐션 스코어를 구하고, 어텐션 분포를 구한 뒤에 이를 사용해, 모든 V벡터를 가중합하여 어텐션 벨류 혹은 컨텍스트 벡터를 구하게 된다. 그리고 이를 모든 Q 벡터에 대해서 반복한다.
그러나 어텐션 함수의 종류는 다양하다. 트랜스포머에서는 내적을 사용하는 어텐션 함수

가 아닌, 특정 값으로 나눠즈는 어텐션함수를 사용한다.

그림을 통해 확인해보자.

우선 단어 I에 대한 Q벡터를 살펴보자. 이 과정은 am에 대한 Q벡터, a에 대한 Q벡터, student에 대한 Q벡터에 대해서도 모드 동일한 과정을 거친다.
위 그림에서 어텐션 스코어는 각각 단어 I가 단어 I,am,a,student와 얼마나 연관되어 있는지를 보여주는 수치이다. 트랜스포머에서는 두 벡터의 내적값을 스케일링하는 값으로 K벡터의 차원을 나타내는 d(k)에 루트를 씌워 사용하였다. 논문에서 d(k)는 d(model)/num_heads라는 식에 따라서 64의 값을 가지므로 루트를 씌운 d(k)는 8의 값을 갖는다.

다음은 어텐션 스코어에 softmax함수를 사용하여 어텐션 분포를 구하고, 각 V벡터와 가중합하여 Attention Value를 출력한다. 이를 단어 I에 대한 어텐션 값 또는 단어 I에 대한 context vector 라고도 부른다. 과연 이 간단한 문장에서는 하나하나 따로 연산을 하는게 큰 문제는 없어보이지만, 많은 양의 문장을 사용할 시에는 과연 따로 연산하는게 효율적일까?
4)행렬 연산으로 일괄 처리
위 과정을 벡터 연산이 아닌 행렬 연산을 사용하면 일괄 계산이 가능하다. 위 과정을 행렬 연산으로 다시 확인해보자.

위 그림에서 Q 행렬을 K행렬로 전치한 행렬과 곱해준다고 해보자. 이렇게 된다면 각각의 단어의 Q벡터와 K벡터의 내적이 각 행렬의 원소가 되는 행렬이 결과로 나온다.
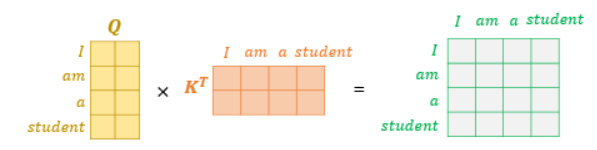
다시 말해 위 그림의 결과 행렬의 값에 전체적으로 d(k)에 루트를 씌운 값으로 나누어주면 이는 각 행과 열이 어텐션 스코어 값을 가지는 행렬이 된다. I 행과 student 열의 값은 I의 Q벡터와 student의 K벡터의 어텐션 스코어와 동일한 행렬이 된다는 의미이다.
위 Attention score matrix를 구하였다면 남은 것은 Attention distribution을 구하고, 이를 사용해 모든 단어에 대한 Attention value를 구하면된다. 이를 위해 score matrix에 softmax함ㅅ수를 사용하고, V행렬을 곱하면 된다.
과정은 다음과 같다.

5)Scaled dot-product attention 구하기
코드를 먼저 살펴보자.
def scaled_dot_product_attention(query,key,value,mask):
# query 크기 : (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
# key 크기 : (batch_size, num_heads, key의 문장 길이, d_model/num_heads)
# value 크기 : (batch_size, num_heads, value의 문장 길이, d_model/num_heads)
# padding_mask : (batch_size, 1, 1, key의 문장 길이)
# Q와 K의 곱. 어텐션 스코어 행렬.
matmul_qk=tf.matmul(query,key,transpose_b=True)
# 스케일링
# dk의 루트값으로 나눠준다.
depth=tf.cast(tf.shape(key)[-1],tf.float32)
logits=matmul_qk/tf.math.sqrt(depth)
# 마스킹. 어텐션 스코어 행렬의 마스킹 할 위치에 매우 작은 음수값을 넣는다.
# 매우 작은 값이므로 소프트맥스 함수를 지나면 행렬의 해당 위치의 값은 0이 된다.
if mask is not None:
logits+=(mask*-1e9)
# 소프트맥스 함수는 마지막 차원인 key의 문장 길이 방향으로 수행된다.
# attention weight : (batch_size, num_heads, query의 문장 길이, key의 문장 길이)
attention_weights=tf.nn.softmax(logits,axis=-1)
# output : (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
output=tf.matmul(attention_weights,value)
return output,attention_weights
앞서 설명한것을 다 이해하였다면 위 코드를 해석하는데는 큰문제가 없을것이라본다. 이제 테스를 해보자.
np.set_printoptions(suppress=True)
temp_k=tf.constant([[10,0,0],
[0,10,0],
[0,0,10],
[0,0,10]],dtype=tf.float32)
temp_v=tf.constant([[1,0],
[10,0],
[100,5],
[1000,6]],dtype=tf.float32)
temp_q=tf.constant([[0,10,0]],dtype=tf.float32)
temp_out,temp_attn=scaled_dot_product_attention(temp_q,temp_k,temp_v,None)
print(temp_attn)
print(temp_out)
tf.Tensor([[0. 1. 0. 0.]], shape=(1, 4), dtype=float32)
tf.Tensor([[10. 0.]], shape=(1, 2), dtype=float32)
6)멀티 헤드 어텐션(Multi-head Attention)
앞서 본 어텐션은 d(model)의 차원을 가진 단어 벡터를 num_heads로 나눈 차원을 가지는 Q,K,V벡터로 바꾸고 어텐션을 수행하였다. 논문 기준 512 차원의 각 단어 벡터를 8로 나누고 64차원의 Q,K,V벡터로 바꾸어 어텐션을 수행한 것이다.
이번에는 num_heads의 의미와 왜 d(model)의 차원을 가진 단어 벡터를 가지고 어텐션을 하지 않고 차원을 축소시킨 벡터로 어텐션을 수행했는지 살펴보자.

트랜스포머 연구진은 한 번의 어텐션을 하는 것보다 여러번의 어텐션을 병렬구조로 사용하는 것이 더 효과적이라 판단했다. 그래서 d(model)의 차원을 num_heads개로 나누어 d(model)/num_heads의 차원을 가지는 Q,K,V에 대해서 num_heads개의 병렬 어텐션을 수행하였다.
그렇다면 병렬 어텐션으로 얻을 수 있는 효과는 무엇이 있을까? 어텐션을 병렬로 수행하여 다른 시각으로 정보들을 수집할 수 있다.
예를들어 앞서 말한 '그 동물은 길을 건너지 않았다. 왜냐하면 그것은 너무 피곤하였기 때문이다'를 살펴보면 단어인 it이 쿼리였다고 해보자. 즉 it에 대한 Q벡터로부터 다른 단어와의 연관도를 구하였을 때 첫 번째 어텐션 헤드는 'it'과 'animal'의 연관도를 높게 본다면, 두 번째 어텐션은 'it'과 'tired'를 높게 볼 수있다. 즉, 다각도로 볼 수 있다는 장점이 있다는 것이다.

병렬 어텐션을 모두 수행하였다면, 모든 어텐션 헤드를 연결(concatenate)한다. 모두 연결된 어텐션 헤드 행렬의 크기는 (seq_len,d(model))가 된다.

어텐션 헤드를 모두 연결한 행렬은 또 다른 가중치 행렬 W(a)를 곱하게 되는데 이렇게 나온 결과 행렬이 멀티-헤드 어텐션의 최종 결과물이다.
인코더의 첫번째 서브픙인 멀티-헤드 어텐션 단계를 끝마쳤을 때, 인코더의 입력으로 들어왔던 행렬의 크기가 아직 유지되고 있음을 기억해두자. 첫 번째 서브층인 멀티-헤드 어텐션과 두 번째 서브층인 포지션 와이즈 피드 포워드 신경망을 지나면서 인코더의 입력으로 들어올 때의 행렬의 크기는 계속 유지되어야 한다. 트랜스포머는 다수의 인코더를 쌓은 형태인데, 인코더에서의 입력의 크기가 출력에서도 동일한 크기로 계속 유지되어야만 다음 인코더에서도 다시 입력이 될 수 있기 때문이다.
7)멀티 헤드 어텐션(Multi-head Attention)구현하기
코드를 살펴보자.
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self,d_model,num_heads,name='multi_head_attention'):
super(MultiHeadAttention,self).__init__(name=name)
self.num_heads=num_heads
self.d_model=d_model
assert d_model%self.num_heads==0
#d_model을 num_heads로 나눈 값.
#논문 기준 64
self.depth=d_model//self.num_heads
#WQ,WK,WV에 해당하는 밀집층 정의
self.query_dense=tf.keras.layers.Dense(units=d_model)
self.key_dense=tf.keras.layers.Dense(units=d_model)
self.value_dense=tf.keras.layers.Dense(units=d_model)
#WQ에 해당하는 밀집층 정의
self.dense=tf.keras.layers.Dense(units=d_model)
#num_heads의 개수만큼 q,k,v를 나누는 함수
def split_heads(self,inputs,batch_size):
inputs=tf.reshape(inputs,shape=(batch_size,-1,self.num_heads,self.depth))
return tf.transpose(inputs,perm=[0,2,1,3])
def call(self,inputs):
query,key,value,mask=inputs['query'],inputs['key'],inputs['value'],inputs['mask']
batch_size=tf.shape(query)[0]
#1.WQ,WK,WV에 해당하는 밀집층 지나기
#q:(batch_size,query의 문장 길이,d_model)
#k:(batck_size,key의 문장 길이,d_model)
#v:(batch_size,value의 문장 길이,d_model)
#참고) 인코더(k,v)-디코더(q)어텐션에서는 query길이와 key,value의 길이는 다를 수 있다.
query=self.query_dense(query)
key=self.key_dense(key)
value=self.value_dense(value)
#2. 헤드 나누기
# q : (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
# k : (batch_size, num_heads, key의 문장 길이, d_model/num_heads)
# v : (batch_size, num_heads, value의 문장 길이, d_model/num_heads)
query=self.split_heads(query,batch_size)
key=self.split_heads(key,batch_size)
value=self.split_heads(value,batch_size)
# 3. 스케일드 닷 프로덕트 어텐션. 앞서 구현한 함수 사용.
# (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
scaled_attention,_=scaled_dot_product_attention(query,key,value,mask)
scaled_attention=tf.transpose(scaled_attention,perm=[0,2,1,3])
# 4. 헤드 연결(concatenate)하기
# (batch_size, query의 문장 길이, d_model)
concat_attention=tf.reshape(scaled_attention,(batch_size,-1,self.d_model))
# 5. WO에 해당하는 밀집층 지나기
# (batch_size, query의 문장 길이, d_model)
outputs=self.dense(concat_attention)
return outputs
8)패딩마스크부터는 다음 포스팅에서 이어가겠다.
[자료 출처]
'Deep Learning > NLP' 카테고리의 다른 글
| 01) 토큰화(Tokenization) (0) | 2021.03.10 |
|---|---|
| 트랜스포머(Transformer)(2) (0) | 2021.03.04 |
| Transfer Learning(전이 학습) (0) | 2021.03.02 |