Batch Normalization
앞전 포스팅에서 각 층의 활성화 값 분포를 관찰하며, 가중치의 초깃값을 적절히 설정하면 각 층의 활성화값 분포가 적당히 퍼지며, 학습이 원만하게 수행됨을 배웠다.
그렇다면,
각 층이 활성화를 적당히 퍼뜨리도록 '강제' 해보면 어떨까?
Batch Normalization Algorithm
배치 정규화가 주목받는 이유는 3가지가 있다.
1) 학습을 빨리 진행할 수 있다(학습 속도 개선)
2) 초깃값에 크게 의존하지 않는다(골치 아픈 초깃값 선택 장애 해소)
3) 오버피팅을 억제한다(드롭아웃 등의 필요성 감소)

배치 정규화는 그 이름과 같이 학습 시 미니배치를 단위로 정규화한다. 데이터 분포가 평균이 0, 분산이 1이 되도록 정규화 하는 것이다.
수식은 다음과 같다.

미니배치 B={x1,x2,x....,xm}이라는 M개의 입력 데이터의 집합에 대해 평균 수식 1과 분산 수식 2를 구한다.
이 처리를 활성화 함수의 앞(혹은 뒤)에 삽입함으로써 데이터 분포가 덜 치우치게 할 수 있다.
또, 배치 정규화 계층마다 이 정규화된 데이터에 고유한 확대와 이동변환을 수행한다.
수식은 다음과 같다.

이 식에서 람다가 확대(scale)를 베타가 이동(shift)를 담당한다. 두 값은 처음에는 각 1,0부터 시작하고 학습하면서 적합한 값으로 조정해간다.
Batch Normalization 효과

MNIST데이터셋을 이용해 배치정규화 진도율을 확인해보았다. 거의 모든 경우에서 배치 정규화를 사용할 때의 학습 진도가 빠른 것을 나타난다. 실제로 이용하지 않는 경우, 초깃값이 잘 분포되어 있지 않으면 학습이 전혀 진행되지 않는 모습도 확인된다.
바른 학습을 위해
기계학습에서는 오버피팅이 문제가 되는 일이 많다.
오버피팅이란 신경망이 훈련데이터에만 지나치게 적응되어 그 외의 데이터에는 제대로 대응하지 못하는 상태를 말한다.
우리의 목표는 기계학습의 범용 성능이다. 훈련 데이터에는 포함되지 않는, 아직 보지 못한 데이터가 주어져도 바르게 식별해내는 모델이 바람직하다.
오버피팅
오버피팅이 일어날 가장 주된 경우는 2가지가 있다.
1)매개변수가 많고 표현력이 높은 모델
2)훈련 데이터가 적을때
다음 코드는 일부로 오버피팅을 일으킨 코딩이다.
(x_train,t_train),(x_test,t_test)=load_mnist(normalize=True)
#오버피팅을 재현하기 위해 학습 데이터 수를 줄임
x_train=x_train[:300]
t_train=t_train[:300]
network=MultiLayerNet(input_size=784,hidden_size_list=[100,100,100,100,100,100],output_size=10)
#학습률이 0.01인 SGD로 매개변수 갱신
optimizer=SGD(lr=0.01)
max_epochs=201
train_size=x_train.shape[0]
batch_size=100
train_loss_list=[]
train_acc_list=[]
test_acc_list=[]
iter_per_epoch=max(train_size/batch_size,1)
epoch_cnt=0
for i in range(100000000):
batch_mask=np.random.choice(train_size,batch_size)
x_batch=x_train[batch_mask]
t_batch=t_train[batch_mask]
grads=network.gradient(x_batch,t_batch)
optimizer.update(network.params,grads)
if i%iter_per_epoch==0:
train_acc=network.accuracy(x_train,t_train)
test_acc=network.accuracy(x_test,t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
epoch_cnt+=1
if epoch_cnt>=max_epochs:
break
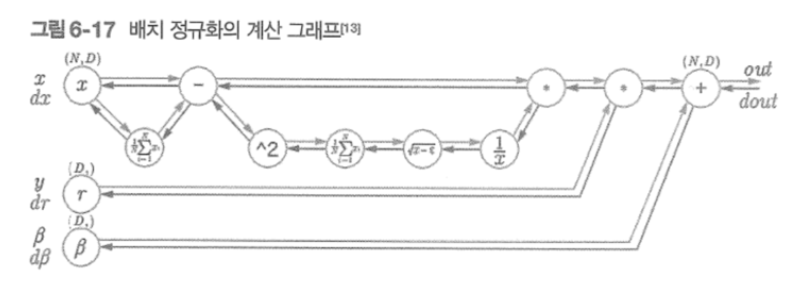
훈련 데이터를 사용하여 측정환 정확도는 100 에폭을 지나는 무렵부터 거의 100%이다.
하지만, 시험 데이터에 대해서는 큰 차이를 보인다. 이처럼 정확도가 크게 벌어지는 것은 훈련데이터에만 적응해버린 것이다.
가중치 감소
오버피팅 억제용으로 예로부터 많이 이용해온 방법 중 가중치 감소(weight decay)가 있다.
이는 큰 가중치에 대해서는 그에 상응하는 큰 페널티를 부과하여 오버피팅을 억제하는 방법이다. 원래 오버피팅은 가중치 매개변수의 값이 커서 발생하는 경우가 많기 때문이다.
이와 비슷한 것이 통계학에서는 회귀분석시 수치적 오류가 나는 것을 피하기위해 표준상관계수분석등을 추가로 하는 이유가 이런 것이다.(?)라고 한번 생각해본다.
신경망 학습의 목적은 손실 함수의 값을 줄이는 것이다. 이때 예를 들어 가중치의 제곱 norm을 손실함수에 더해주는 방법도 있다.
드롭아웃
가중치 감소는 간단하게 구현할 수 있고 어느 정도 지나친 학습을 억제할 수 있다. 그러나 신경망 모델이 복잡해지면 가중치 감소만으로는 대응하기 어려워진다. 이를 흔히 드롭아웃(drop out)이라는 기법을 이용한다.
드롭아웃이란 뉴런을 임의로 삭제하면서 학습하는 방법이다.
훈련 때 은닉층의 뉴런을 무작위로 골라 삭제한다. 삭제된 뉴런은 아래 그림과 같이 신호를 전달하지 않게 된다. 훈련때는 데이터를 흘릴 때마다 삭제할 뉴런을 무작위로 선택하고, 시험 떄는 모든 뉴런에 신호를 전달한다.
단, 시험 때는 각 뉴런의 출력에 훈련 때 삭제한 비율을 곱하여 출력한다.
코딩을 살펴보자.
class Dropout:
def __init__(self,dropout_ratio=0.5):
self.dropout_ratio=dropout_ratio
self.mask=None
def forward(self,x,train_flg=True):
if train_flg:
self.mask=np.random.rand(*x.shape)>self.dropout_ratio
return x*self.mask
def backward(self,dout):
return dout*self.mask핵심은 훈련 시에는 순전파 때마다 self.mask에 삭제할 뉴런을 False로 표시한다는 것이다.
self.mask는 x와 형상이 같은 배열을 무작위로 생성하고, 그 값이 dropout_ratio보다 큰 원소만 True로 설정한다.
역전파 때의 동작은 ReLU와 같다.
즉, 순전파때 신호를 통과시키는 뉴런은 역전파 때도 신호를 그대로 통과시키고, 순전파 때 통과시키지 않은 뉴런은 역전파 때도 신호를 차단한다.

위 그림과 같이 드롭아웃을 적용하니 훈련 데이터와 시험 데이터에 대한 정확도 차이가 줄었음을 볼 수있다.
또한, 훈련 데이터에 대한 정확도가 100%에 도달하지도 않게 되었다.
[Note]
기계학습에서는 앙상블 학습(ensemble learning)을 애용한다.
앙상블 학습은 개별적으로 학습시킨 여러 모델의 출력을 평균내어 추론하는 방식이다.
신경망의 맥락에서 얘기하면, 가령 같은 구조의 네크워크를 5개 준비하여 따로따로 학습시키고, 시험 때는 그 5개의 출력을 평균 내어 답하는 것이다.
앙상블 학습을 수행하면 신경망의 정확도가 몇% 정도 개선된다는 것이 실험적으로 알려져 있다.
앙상블 학습은 드롭아웃과 밀접하다.
드롭아웃이 학습 때 뉴런을 무작위로 삭제하는 행위를 매번 다른 모델을 학습시키는 것으로 해석할 수 있기 때문이다.
그리고 추론 때는 뉴런의 출력에 삭제한 비율(이를테면 0.5 등)을 곱함으로써 앙상블 학습에서 여러 모델의 평균을 내는 것과 같은 효과를 얻는 것이다.
즉, 드롭아웃은 앙상블 학습과 같은 효과를 (대략) 하나의 네트워크로 구현했다고 생각할 수 있다.
적절한 하이퍼파라미터 값 찾기
신경망에는 하이퍼파라미터가 다수 등장한다. 여기서 말하는 하이퍼파라미터는, 예를 들면 각 층의 뉴런 수, 배치 크기, 매개변수 갱신 시의 학습률과 가중치 감소 등이다. 이러한 하이퍼파라미터의 값을 적절히 설정하지 않으면 모델의 성능이 크게 떨어지기도 한다. 하이퍼라라미터의 값은 매우 중요하지만 그 값을 결정하기까지는 일반적으로 많은 시행착오를 겪는다.
검증 데이터
앞으로 하이퍼파라미터를 다양한 값으로 설정하고 검증할 텐데, 여기서 주의할 점은 하이퍼파라미터의 성능을 평가할 때는 시험 데이터를 사용해서는 안된다.
같은 성능 평가인데 안되는 이유가 무엇일까?
대답은 시험 데이터를 사용하여 하이퍼파라미터를 조정하면 하이퍼파라미터 값이 시험 데이터에 오버피팅되기 때문이다. 다시 말해, 하이퍼파라미터 값의 '좋음'을 시험 데이터로 확인하게 되므로 하이퍼파라미터 값이 시험 데이터에만 적합하도록 조정되어 버린다.
그래서 하이퍼파라미터를 조정할 떄는 하이퍼파라미터 전용 확인 데이터가 필요하다. 하이퍼파라미터 조정용 데이터를 일반적으로 검증데이터(validation data)라고 부른다.
[Note]
훈련 데이터는 매개변수(가중치와 편향)의 학습에 이용하고, 검증 데이터는 하이퍼파라미터의 성능을 평가하는 데 이용한다.
시험 데이터는 범용 성능을 확인하기 위해서 마지막에 (이상적으로는 한번만) 이용한다.
-훈련데이터: 매개변수 학습
-검증데이터: 하이퍼파라미터 성능 평가
-시험데이터: 신경망의 범용 성능 평가
코드로 살펴보자.
(x_train,t_train),(x_test,t_test)=load_mnist()
#훈련 데이터를 뒤섞는다.
x_train,t_train=shuffle_dataset(x_train,t_train)
#20%를 검증 데이터로 분할
validation_rate=0.2
validation_num=int(x_train.shape[0]*validation_rate)
x_val=x_train[:validation_num]
t_val=t_train[:validation_num]
x_train=x_train[validation_num:]
t_train=t_train[validation_num:]위 코드는 훈련 데이터를 분리하기 전에 입력 데이터와 정답 레이블을 섞는다. 이어서 검증 데이터를 사용하여 하이퍼파라미터를 최적화하는 기법을 살펴보자.
하이퍼파라미터 최적화
하이퍼파라미터를 최적화할 때의 핵심은 하이퍼파라미터의 '최적 값'이 존재하는 범위를 줄여나간다는 것이다.
범위를 조금씩 줄이려면 우선 대략적인 범위를 설정하고 그 범위에서 무작위로 하이퍼파라미터 값을 골라낸(샘플링) 후, 그 값으로 정확도를 평가한다.
[Note]
신경망의 하이퍼파라미터 최적화에서는 그리드 서치(grid search)같은 규칙적인 탐색보다는 무작위로 샘플링해 탐색하는 편이 좋은 결과를 낸다고 알려져 있다. 이는 최종 정확도에 미치는 영향력이 하이퍼파라미터마다 다르기 때문이다.
하이퍼파라미터의 범위는 '대략적' 지정이 가장 효과적이다. 실제로도 0.001에서 1000사이와 같이 10의 거듭제곱 단위로 범위를 지정한다. 이를 log scale이라고 부른다.
정리해보면,
1)하이퍼파라미터 값의 범위를 설정한다.
2)설정된 범위에서 하이퍼파라미터의 값을 무작위로 추출한다.
3)2단계에서 샘플링한 하이퍼파라미터 값을 사용하여 학습하고 검증 데이터로 정확도를 평가한다. (단, epoch은 작게 설정)
4)2단계와 3단계를 특정 횟수(log scale)반복하여, 그 정확도의 결과를 보고 하이퍼파라미터의 범위를 좁힌다.
MNIST 예제를 통해 결과를 살펴보면,


학습이 잘 진행될 때의 학습률은 0.001~0.01, 가중치 감소 계수는 10^-8~10^-6정도라는 것을 알 수 있다.
이처럼 잘될 것 같은 값의 범위를 관찰하고 범위를 좁혀가면된다.
'Deep Learning > 밑바닥부터 시작하는 딥러닝(1)' 카테고리의 다른 글
| Chapter 7. 합성곱 신경망(CNN)(2) (0) | 2021.03.10 |
|---|---|
| Chapter 7. 합성곱 신경망(CNN)(1) (0) | 2021.03.09 |
| Chapter 6. 학습 관련 기술들(2) (0) | 2021.03.03 |
| Chapter 6. 학습 관련 기술들(1) (0) | 2021.03.02 |
| Chapter 5. 오차역전파법 (0) | 2021.01.25 |