이번 프로젝트는 아파트 실거래가를 예측하는 것이다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import timeit
import sklearn
import warnings
warnings.filterwarnings('ignore')
import sys
train_data=pd.read_csv('d:/data/real_estate/train.csv')
test_data=pd.read_csv('d:/data/real_estate/test.csv')
print('train.csv. Shape: ',train_data.shape)
print('test.csv. Shape: ', test_data.shape)
train.csv. Shape: (1216553, 13)
test.csv. Shape: (5463, 12)훈련데이터는 총 120만개정도이고 , 테스트 데이터는 5400여개가 존재한다.
각 데이터의 정보를 간략하게 살펴보자.
train_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1216553 entries, 0 to 1216552
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 transaction_id 1216553 non-null int64
1 apartment_id 1216553 non-null int64
2 city 1216553 non-null object
3 dong 1216553 non-null object
4 jibun 1216553 non-null object
5 apt 1216553 non-null object
6 addr_kr 1216553 non-null object
7 exclusive_use_area 1216553 non-null float64
8 year_of_completion 1216553 non-null int64
9 transaction_year_month 1216553 non-null int64
10 transaction_date 1216553 non-null object
11 floor 1216553 non-null int64
12 transaction_real_price 1216553 non-null int64
dtypes: float64(1), int64(6), object(6)
memory usage: 120.7+ MBtest_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5463 entries, 0 to 5462
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 transaction_id 5463 non-null int64
1 apartment_id 5463 non-null int64
2 city 5463 non-null object
3 dong 5463 non-null object
4 jibun 5463 non-null object
5 apt 5463 non-null object
6 addr_kr 5463 non-null object
7 exclusive_use_area 5463 non-null float64
8 year_of_completion 5463 non-null int64
9 transaction_year_month 5463 non-null int64
10 transaction_date 5463 non-null object
11 floor 5463 non-null int64
dtypes: float64(1), int64(5), object(6)
memory usage: 512.3+ KB훈련데이터와 테스트데이터의 레이블을 살펴보면 훈련데이터에만 transaction_real_price가 있는것을 확인할 수 있다. 이는 결국 훈련 데이터를 통해 가격을 예측해보기 위한점이다.
[Train Column name Description]
- transaction_id : 아파트 거래에 대한 유니크한 아이디
- apartment_id : 아파트 아이디
- city : 도시
- dong : 동
- jibun : 지번
- apt : 아파트단지 이름
- addr_kr : 주소
- exclusive_use_area : 전용면적
- year_of_completion : 설립일자
- transaction_year_month : 거래년월
- transaction_date : 거래날짜
- floor : 층
- transaction_real_price : 실거래가 (target variable)
이제 결측값이 있는지 확인해보자.
train_null=train_data.drop('transaction_real_price',axis=1).isnull().sum()/len(train_data)*100
test_null=test_data.isnull().sum()/len(test_data)*100
pd.DataFrame({'train_null_count': train_null,'test_null_count':test_null})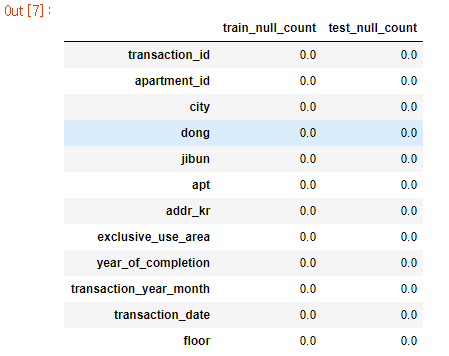
딱히, 결측치는 존재하지 않는다.
간단하게 훈련 데이터를 살펴보자.
train_data.head()
transaction_id apartment_id city dong jibun apt addr_kr exclusive_use_area year_of_completion transaction_year_month transaction_date floor transaction_real_price
0 0 7622 서울특별시 신교동 6-13 신현(101동) 신교동 6-13 신현(101동) 84.82 2002 200801 21~31 2 37500
1 1 5399 서울특별시 필운동 142 사직파크맨션 필운동 142 사직파크맨션 99.17 1973 200801 1~10 6 20000
2 2 3578 서울특별시 필운동 174-1 두레엘리시안 필운동 174-1 두레엘리시안 84.74 2007 200801 1~10 6 38500
3 3 10957 서울특별시 내수동 95 파크팰리스 내수동 95 파크팰리스 146.39 2003 200801 11~20 15 118000
4 4 10639 서울특별시 내수동 110-15 킹스매너 내수동 110-15 킹스매너 194.43 2004 200801 21~31 3 120000탐색적 데이터 분석 및 처리
훈련데이터 ['transaction_real_price']레이블의 통계적 요약을 살펴보면 다음과 같다.
train_data['transaction_real_price'].describe()
count 1.216553e+06
mean 3.822769e+04
std 3.104898e+04
min 1.000000e+02
25% 1.900000e+04
50% 3.090000e+04
75% 4.700000e+04
max 8.200000e+05
Name: transaction_real_price, dtype: float64평균 38827 Min: 100 MAX: 820000 표준편차:31048
이를 그래프로 막대그래프와 왜도 첨도를 통해 그래프를 살펴보자.
왜도(Skewness): 왼쪽으로 치우쳐져 있을수록 값이 크다.
첨도(Kurtosis): 첨도 값이 3에 가까울 경우 정규분포에 근사한다. 첨도 값이 클수록 뾰족하고 값이 작을수록 완만해진다.
f,ax=plt.subplots(figsize=(8,6))
sns.distplot(train_data['transaction_real_price'])
print("%s->Skewness: %f, Kurtosis: %f" % ('transaction_real_price',train_data['transaction_real_price'].skew(),train_data['transaction_real_price'].kurt()))
transaction_real_price->Skewness: 3.407169, Kurtosis: 24.839821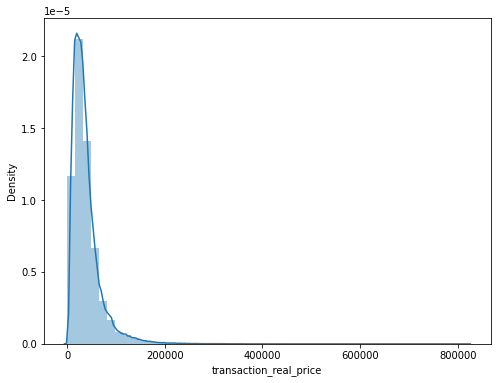
이 그래프를 정규화에 근사시키기 위해 log1p 함수를 이용해 로그를씌워 다시 한번확인해보자.
train_data['transaction_real_price'] = np.log1p(train_data['transaction_real_price'])
print("%s -> Skewness: %f, Kurtosis: %f" % ('transaction_real_price',train_data['transaction_real_price'].skew(),train_data['transaction_real_price'].kurt()))
transaction_real_price -> Skewness: -0.094932, Kurtosis: 0.248866
f,ax=plt.subplots(figsize=(8,6))
sns.distplot(train_data['transaction_real_price'])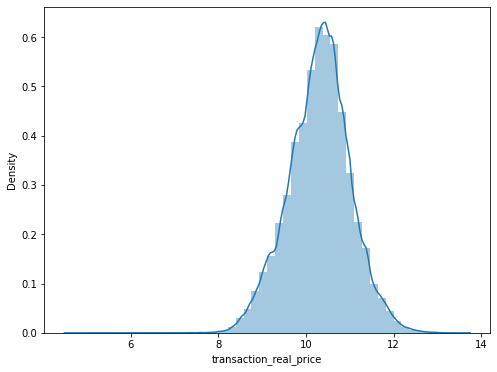
칼럼들의 상관관계
각 칼럼들간의 상관관계를 확인해보자.
k=train_data.shape[1]
corrmat=train_data.corr()
cols=corrmat.nlargest(k,'transaction_real_price')['transaction_real_price'].index
cm=np.corrcoef(train_data[cols].values.T)
f,ax=plt.subplots(figsize=(8,6))
sns.heatmap(data=cm,annot=True,square=True,fmt='.2f',linewidths=5,cmap='Reds',yticklabels=cols.values,xticklabels=cols.values)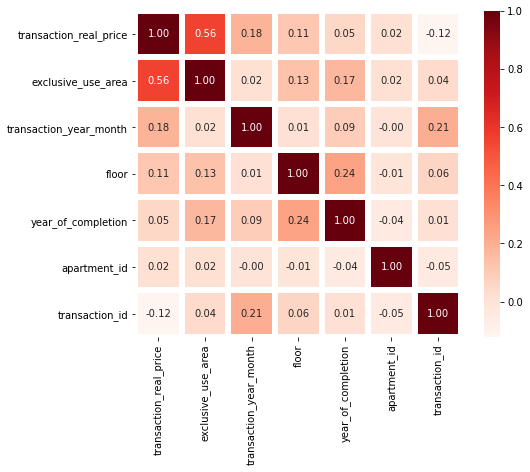
훈련데이터의 'apartment_id' 칼럼의 unique_value의 갯수를 확인해보자.
len(train_data['apartment_id'].unique())
12533
이후 'transaction_id'를 따로 변수로 지정한 후, 본래의 데이터프레임에서는 없애주자.
train_id=train_data['transaction_id']
train=train_data.drop('transaction_id',axis=1)
test_id=test_data['transaction_id']
test=test_data.drop('transaction_id',axis=1)Floor(층)
가설) 층수가 높아질수록 집값도 높아진다.
'floor' 과 'transaction_real_price'의 연관성을 확인하기 위해 산점도표에 케스팅해보자.
f,ax=plt.subplots(figsize=(8,6))
plt.scatter(train['floor'],train['transaction_real_price'])
plt.xlabel('floor')
plt.ylabel('transaction_real_price')
plt.show()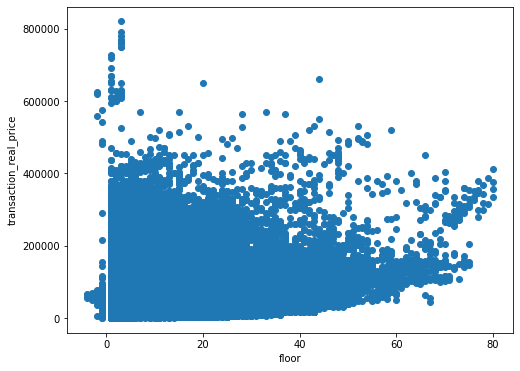
위 그래프를 확인해보면 층수가 높아질수록 집값도 높아진다라는 본인의 생각은 틀린것을 알 수 있다.
그렇다면,
floor(층수)칼럼에 대해서 막대그래프를 통한 분포표도 확인해보자.
f,ax=plt.subplots(figsize=(8,6))
sns.distplot(train['floor'])
print('%s->Skewness: %f, Kurtosis: %f'% ('floor',train['floor'].skew(),train['floor'].kurt()))
floor->Skewness: 1.324710, Kurtosis: 3.796603exclusive_use_area(전용면적)
가설) 전용면적이 넓어지면 넓어질수록 집값은 비싸다
우선 훈련데이터의 'exclusive_use_area'를 간단하게 통계적 요약으로 살펴보자.
train['exclusive_use_area'].describe()
count 1.216553e+06
mean 7.816549e+01
std 2.915113e+01
min 9.260000e+00
25% 5.976000e+01
50% 8.241000e+01
75% 8.497000e+01
max 4.243200e+02
Name: exclusive_use_area, dtype: float64Mean: 78.1 Min: 9.2 Max: 424.3
이를 산점도표에 케스팅하여 전용면적과 집값의 연관성을 확인해보자.
f,ax=plt.subplots(figsize=(8,6))
plt.scatter(train['exclusive_use_area'],train['transaction_real_price'])
plt.xlabel('exclusive_use_area')
plt.ylabel('transaction_real_price')
plt.show()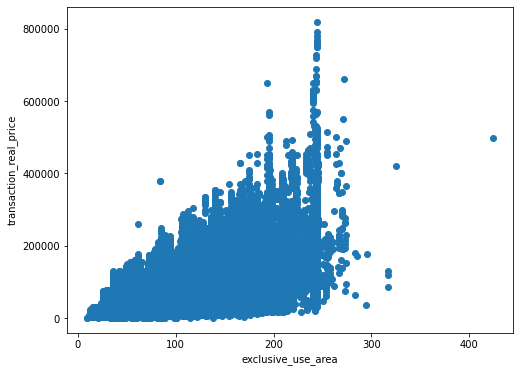
대략 위 산점도표를 살펴보면, 전용면적이 넓어질수록 집값도 올라가는 경향을 보인다. 그러므로 가설은 맞다고 가정하자.
이상치들을 확인해보자.
train[train['exclusive_use_area']>400]
apartment_id city dong jibun apt addr_kr exclusive_use_area year_of_completion transaction_year_month transaction_date floor transaction_real_price
563870 12633 서울특별시 도곡동 193-1 힐데스하임빌라 도곡동 193-1 힐데스하임빌라 424.32 1998 201604 11~20 10 498000train[(train['exclusive_use_area']<150)&(train['transaction_real_price']<200)]
apartment_id city dong jibun apt addr_kr exclusive_use_area year_of_completion transaction_year_month transaction_date floor transaction_real_price
722888 6225 부산광역시 범전동 263-5 서면 범전동 263-5 서면 138.25 1974 201606 21~30 -1 100크게 이상치라고 판단할수 있는 건 없는것 같다.
이를 한번더 막대 그래프로 살펴보자.
f,ax=plt.subplots(figsize=(8,6))
sns.distplot(train['exclusive_use_area'])
print("%s->Skewness: %f, Kurtosis= %f"% ('exclusive_use_area',train['exclusive_use_area'].skew(),train['exclusive_use_area'].kurt()))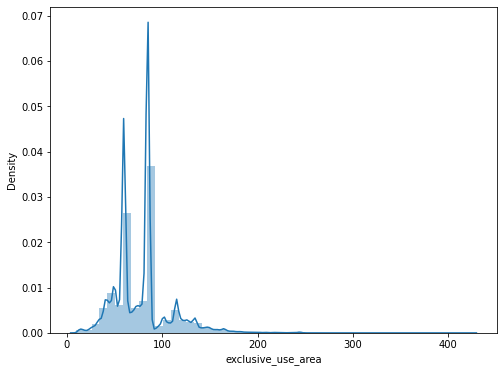
transaction_year_month(거래 년,월)
훈련데이터와 테스트데이터에 있는 년월 칼럼을 따로 뽑아와 새로운 칼럼으로 만들어보자.
train_test_data=[train,test]
for dataset in train_test_data:
dataset['transaction_year_month']=dataset['transaction_year_month'].astype(str)
dataset['year']=dataset['transaction_year_month'].str[:4].astype(int)
dataset['month']=dataset['transaction_year_month'].str[4:6].astype(int)
dataset['transaction_year_month']=dataset['transaction_year_month'].astype(int)
년도 별로 그래프를 확인해보자.
f,ax=plt.subplots(figsize=(8,6))
sns.boxplot(train['year'],train['transaction_real_price'])
plt.show()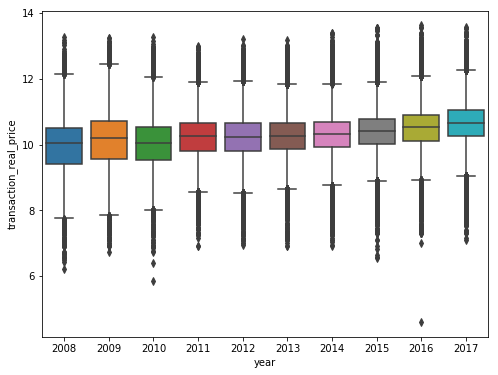
보면 2016년도에 이상치같이 보이는 것이 하나 생겨있다. 이를 좀더 확인해보자.
train[(train['year']==2016)&(train['transaction_real_price']<150)]
apartment_id city dong jibun apt addr_kr exclusive_use_area year_of_completion transaction_year_month transaction_date floor transaction_real_price year month
722888 6225 부산광역시 범전동 263-5 서면 범전동 263-5 서면 138.25 1974 201606 21~30 -1 100 2016 6서면 아파트가 값이 낮다.
그렇다면 서면 전체에 대해서 한번 확인해보자.
train[train['apt']=='서면'] apartment_id city dong jibun apt addr_kr exclusive_use_area year_of_completion transaction_year_month transaction_date floor transaction_real_price year month
695725 6238 부산광역시 전포동 산99-46 서면 전포동 산99-46 서면 57.59 1976 201105 21~31 3 5900 2011 5
696834 6238 부산광역시 전포동 산99-46 서면 전포동 산99-46 서면 57.59 1976 201108 21~31 1 7500 2011 8
700884 6225 부산광역시 범전동 263-5 서면 범전동 263-5 서면 88.93 1974 201206 1~10 1 25000 2012 6
702589 6238 부산광역시 전포동 산99-46 서면 전포동 산99-46 서면 57.59 1976 201212 21~31 5 6000 2012 12
702876 6238 부산광역시 전포동 산99-46 서면 전포동 산99-46 서면 57.59 1976 201301 11~20 4 7400 2013 1
703979 6238 부산광역시 전포동 산99-46 서면 전포동 산99-46 서면 57.59 1976 201304 1~10 1 7000 2013 4
711024 6238 부산광역시 전포동 산99-46 서면 전포동 산99-46 서면 57.59 1976 201407 21~31 5 7000 2014 7
712441 6238 부산광역시 전포동 산99-46 서면 전포동 산99-46 서면 57.59 1976 201410 21~31 3 8800 2014 10
713864 6238 부산광역시 전포동 산99-46 서면 전포동 산99-46 서면 57.59 1976 201501 1~10 4 7750 2015 1
721684 6238 부산광역시 전포동 산99-46 서면 전포동 산99-46 서면 57.59 1976 201604 1~10 1 8600 2016 4
722888 6225 부산광역시 범전동 263-5 서면 범전동 263-5 서면 138.25 1974 201606 21~30 -1 100 2016 6
723957 6225 부산광역시 범전동 263-5 서면 범전동 263-5 서면 55.04 1974 201608 21~31 2 23200 2016 8
726597 6238 부산광역시 전포동 산99-46 서면 전포동 산99-46 서면 57.59 1976 201612 11~20 4 6650 2016 12
1186983 6225 부산광역시 범전동 263-5 서면 범전동 263-5 서면 34.08 1974 201702 11~20 1 16400 2017 2
1189112 6238 부산광역시 전포동 산99-46 서면 전포동 산99-46 서면 57.59 1976 201706 21~30 3 9300 2017 6
1189212 6225 부산광역시 범전동 263-5 서면 범전동 263-5 서면 54.15 1974 201706 1~10 5 26200 2017 6서면 아파트 값이 전체적으로 싼것은아니다.. 그럼 뭐때문에 이렇게 값이 떨어진걸까? 확인해보니 floor=-1 인것을 볼수있다.
그렇다면 다른 -1층은 어떨까?
train[train['floor']==-1].sort_values('transaction_real_price') apartment_id city dong jibun apt addr_kr exclusive_use_area year_of_completion transaction_year_month transaction_date floor transaction_real_price year month
722888 6225 부산광역시 범전동 263-5 서면 범전동 263-5 서면 138.250 1974 201606 21~30 -1 100 2016 6
651052 1514 부산광역시 대청동4가 75-176 근영빌라2동 대청동4가 75-176 근영빌라2동 47.170 1996 200809 21~30 -1 1300 2008 9
651087 1513 부산광역시 대청동4가 75-181 근영빌라1동 대청동4가 75-181 근영빌라1동 59.890 1996 200810 11~20 -1 2500 2008 10
651641 1514 부산광역시 대청동4가 75-176 근영빌라2동 대청동4가 75-176 근영빌라2동 47.170 1996 201101 21~31 -1 3200 2011 1
674249 9764 부산광역시 동삼동 213-19 조은아크로빌 동삼동 213-19 조은아크로빌 46.800 2001 201506 11~20 -1 3500 2015 6
... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
537384 10310 서울특별시 청담동 102-13 청담파라곤Ⅱ 2단지 청담동 102-13 청담파라곤Ⅱ 2단지 241.880 2010 201012 11~20 -1 290000 2010 12
1095417 11320 서울특별시 한남동 810 한남더힐 한남동 810 한남더힐 212.524 2011 201705 21~31 -1 480000 2017 5
1095416 11320 서울특별시 한남동 810 한남더힐 한남동 810 한남더힐 212.524 2011 201705 21~31 -1 490000 2017 5
23585 11320 서울특별시 한남동 810 한남더힐 한남동 810 한남더힐 240.230 2011 201612 1~10 -1 543000 2016 12
23376 11320 서울특별시 한남동 810 한남더힐 한남동 810 한남더힐 240.230 2011 201610 11~20 -1 575000 2016 10지하 1층 치고 비싼곳도 있는것이 확인된다. 그러므로 지하1층은 값이 싸다라는 가정도 패스.
그러면 transaction_real_price가 100인 위치를 한번 싹다 확인해보자.
train[train['jibun']=='263-5'].sort_values('floor')
apartment_id city dong jibun apt addr_kr exclusive_use_area year_of_completion transaction_year_month transaction_date floor transaction_real_price year month
722888 6225 부산광역시 범전동 263-5 서면 범전동 263-5 서면 138.25 1974 201606 21~30 -1 100 2016 6
700884 6225 부산광역시 범전동 263-5 서면 범전동 263-5 서면 88.93 1974 201206 1~10 1 25000 2012 6
1186983 6225 부산광역시 범전동 263-5 서면 범전동 263-5 서면 34.08 1974 201702 11~20 1 16400 2017 2
723957 6225 부산광역시 범전동 263-5 서면 범전동 263-5 서면 55.04 1974 201608 21~31 2 23200 2016 8
1189212 6225 부산광역시 범전동 263-5 서면 범전동 263-5 서면 54.15 1974 201706 1~10 5 26200 2017 6확인해보니 같은 위치의 가격에 비해 price가 100인 값만 현저하게 작다..
이것을 이상치라고 판단하고 넘어가야하는가... 고민된다 통계적 계산을 통해 이상치 판단 근거를 만들 수 있지만 이는 다음에 해보는 것으로하고 우선 넘어가자.
그 다음은 월별과 가격의 연관성을 확인해보자.
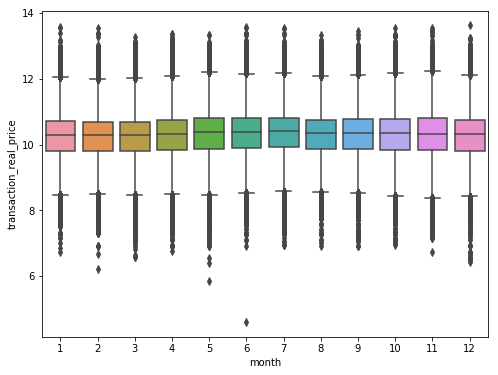
위 그림을 보면 6월에 이상치같은 것이 있는데 이는 위에서 얘기한 price:100인 집이다.
year_of_completion(설립일자)
f,ax=plt.subplots(figsize=(22,6))
sns.boxplot(train['year_of_completion'],train['transaction_real_price'])
plt.show()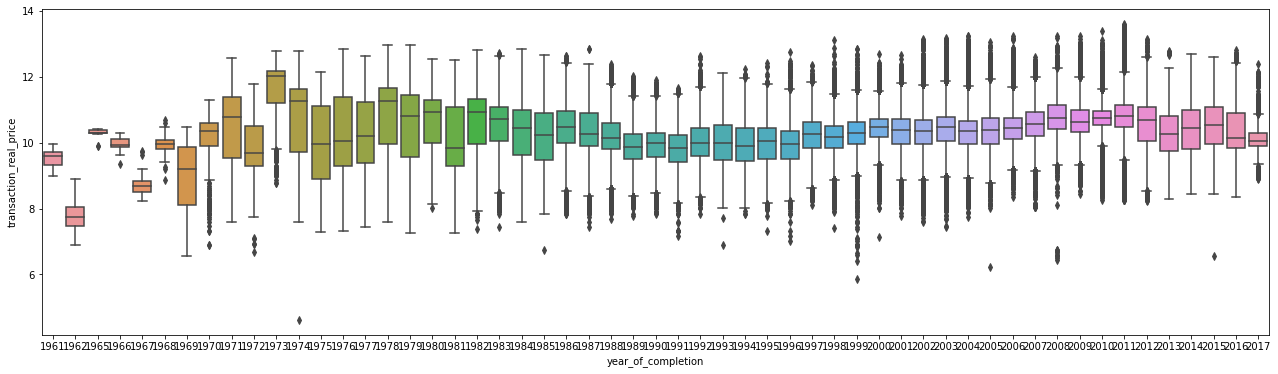
다음 설립일자에서... 너무많지만 가장 이상치같이 보이는 점을 확대해서 확인해보자..

1974년도에 가장 낮은 값이 있었는데 이는 무엇인지 확인해보자.
train[train['year_of_completion']==1974].sort_values('transaction_real_price',ascending=True) apartment_id city dong jibun apt addr_kr exclusive_use_area year_of_completion transaction_year_month transaction_date floor transaction_real_price year month
722888 6225 부산광역시 범전동 263-5 서면 범전동 263-5 서면 138.25 1974 201606 21~30 -1 4.615121 2016 6
350513 12414 서울특별시 화곡동 354-54 화곡동복지 화곡동 354-54 화곡동복지 53.94 1974 201206 21~30 1 7.601402 2012 6
689192 7162 부산광역시 가야동 385-2 시영 가야동 385-2 시영 39.67 1974 201004 21~30 6 7.696667 2010 4
679153 7162 부산광역시 가야동 385-2 시영 가야동 385-2 시영 39.67 1974 200807 11~20 4 7.824446 2008 7
678316 7162 부산광역시 가야동 385-2 시영 가야동 385-2 시영 39.67 1974 200805 11~20 5 7.863651 2008 5
... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
1163472 4695 서울특별시 반포동 757 반포 주공1단지 반포동 757 반포 주공1단지 140.33 1974 201706 11~20 2 12.706851 2017 6
1164677 4695 서울특별시 반포동 757 반포 주공1단지 반포동 757 반포 주공1단지 140.33 1974 201709 11~20 3 12.736704 2017 9
1164022 4695 서울특별시 반포동 757 반포 주공1단지 반포동 757 반포 주공1단지 140.33 1974 201707 21~31 5 12.765691 2017 7
1164377 4695 서울특별시 반포동 757 반포 주공1단지 반포동 757 반포 주공1단지 140.33 1974 201708 1~10 3 12.765691 2017 8
1164370 4695 서울특별시 반포동 757 반포 주공1단지 반포동 757 반포 주공1단지 140.33 1974 201708 1~10 4 12.779876 2017 8이또한 똑같은 데이터였다..
변수 카테고리화
city(도시)
우선 서울특별시와 부산광역시를 레이블 0,1로 구분시켜 다시 데이터프레임을 구성하자.
replace_name={'서울특별시':0,'부산광역시':1}
train=train.replace({'city':replace_name})
test=test.replace({'city':replace_name})
f,ax=plt.subplots(figsize=(8,6))
sns.boxplot(train['city'],train['transaction_real_price'])
plt.show()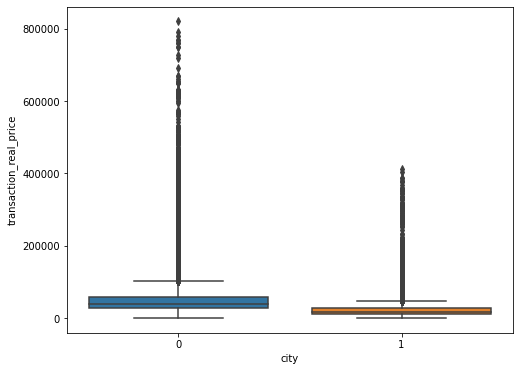
보니 서울이 부산보다 집값이 높은것을 확인할 수 있다. 거래량도 확인해보자
f,ax=plt.subplots(figsize=(8,6))
sns.countplot(train['city'])
plt.show()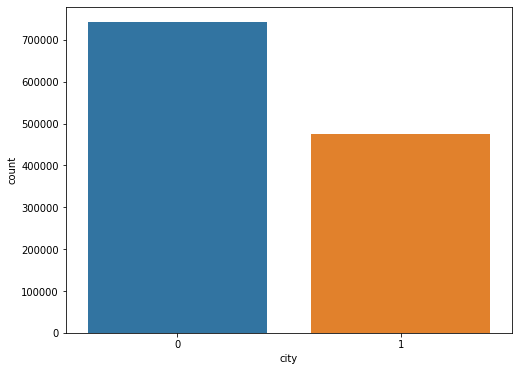
이를 통해 집값은 서울이 더 높고, 거래량도 서울이 더 높은것을 확인할 수 있다.
addr_kr(주소)
동, 지번, 아파트단지이름을 합친 것을 addr_kr로 하였는데 이는 그냥 삭제해버리자.
train=train.drop('addr_kr',axis=1)
test=test.drop('addr_kr',axis=1)dong(동)
데이콘 튜토리얼 샘플코드에서는 한강의 유무에 따른 feature를 하나 생성해준다. 그러므로 본인도 만들어놓아본다.
train['hangang']=train['dong'].isin(['성수동1가','삼성동','이촌동','공덕동','서교동','한강로3가','목동']).astype(int)
test['hangang']=train['dong'].isin(['성수동1가','삼성동','이촌동','공덕동','서교동','한강로3가','목동']).astype(int)len(train['dong'].unique())
473dong은 그 지역을 그룹핑한 것이다. 그러므로 지역에 따라 가격차이를 확인해 줄 수 있다.
아파트 거래가격의 평균순으로 데이터를 레이블링해보자.
train_dong=train[['transaction_real_price','dong']].groupby('dong').mean().sort_values('transaction_real_price').reset_index()
train_dong.head()dong transaction_real_price
0 신선동3가 5500.000000
1 장안읍 명례리 5508.333333
2 신창동2가 5531.250000
3 봉래동5가 5732.546012
4 중앙동4가 6312.500000dong_num={}
for i in range(len(train_dong)):
dong=train_dong['dong'].iloc[i]
dong_num[dong]=i
dong_num
{'신선동3가': 0,
'장안읍 명례리': 1,
'신창동2가': 2,
'봉래동5가': 3,
'중앙동4가': 4,
'장충동2가': 5,
'신선동2가': 6,
'부평동2가': 7,
'필동1가': 8,
'아미동2가': 9,
'초장동': 10,
'수정동': 11,
'기장읍 대변리': 12,
'동광동5가': 13,
'보수동1가': 14,
'남항동3가': 15,
'대청동1가': 16,
'누상동': 17,
'반송동': 18,
'기장읍 서부리': 19,
'동삼동': 20,
'영등포동3가': 21,
'일광면 이천리': 22,
'봉래동4가': 23,
'서동': 24,
'일광면 삼성리': 25,
'대청동4가': 26,
'영등포동2가': 27,
'덕천동': 28,
'모라동': 29,
'감만동': 30,
'미근동': 31,
'장림동': 32,
'학장동': 33,
'동대신동3가': 34,
'구평동': 35,
'보수동2가': 36,
...
'대치동': 464,
'서빙고동': 465,
'한남동': 466,
'반포동': 467,
'회현동2가': 468,
'용산동5가': 469,
'청암동': 470,
'압구정동': 471,
'장충동1가': 472}train=train.replace({'dong': dong_num})
test=test.replace({'dong':dong_num})
train.head()apartment_id city dong jibun apt exclusive_use_area year_of_completion transaction_year_month transaction_date floor transaction_real_price year month hangang
0 7622 0 335 6-13 신현(101동) 84.82 2002 200801 21~31 2 37500 2008 1 0
1 5399 0 408 142 사직파크맨션 99.17 1973 200801 1~10 6 20000 2008 1 0
2 3578 0 408 174-1 두레엘리시안 84.74 2007 200801 1~10 6 38500 2008 1 0
3 10957 0 459 95 파크팰리스 146.39 2003 200801 11~20 15 118000 2008 1 0
4 10639 0 459 110-15 킹스매너 194.43 2004 200801 21~31 3 120000 2008 1 0Jibun(지번)
지번의 unique_value를 확인해보자.
len(train['jibun'].unique())
8961train_jibun=train[['transaction_real_price','jibun']].groupby('jibun').mean().sort_values('transaction_real_price').reset_index()
train_jibun.head() jibun transaction_real_price
0 산3-148 1428.263889
1 737-1 1852.413793
2 741-1 1855.584416
3 11-174 2000.000000
4 1181-4 2043.055556
apt(아파트)
아파트의 unique_value를 확인해보자
len(train['apt'].unique())
10440train_apt=train[['transaction_real_price','apt']].groupby('apt').mean().sort_values('transaction_real_price').reset_index()
train_apt.head() apt transaction_real_price
0 좌천시민(737-1) 1852.413793
1 좌천시민(741-1) 1855.584416
2 수정(1181-4) 2043.055556
3 수정(1175-1) 2111.785714
4 수정(1186-1) 2292.333333확인해보니 지번과 아파트 데이터는 unique_value가 너무 많다.. 따로 레이블링은 하지말자..
transaction_date(거래 기간)
위 데이터는 처음 거래시작한 day와 거래가 끝난 day의 차이를 칼럼으로 변경시켜주자.
train['day_diff']=train['transaction_date'].str.extract('(~\d+)')[0].str[1:].astype(int)-train['transaction_date'].str.extract('(\d+~)')[0].str[:-1].astype(int)
test['day_diff']=test['transaction_date'].str.extract('(~\d+)')[0].str[1:].astype(int)-test['transaction_date'].str.extract('(\d+~)')[0].str[:-1].astype(int)이것에 대해 unique_value를 확인해보자.
len(train['transaction_date'].unique())
6거래기간은 unique_value가 6개이므로 이는 레이블링 처리를 해주자.
train_date=train[['transaction_real_price','transaction_date']].groupby('transaction_date').mean().sort_values('transaction_real_price').reset_index()
train_date.head()transaction_date transaction_real_price
0 21~29 33055.585346
1 21~28 37182.344295
2 1~10 37732.015054
3 11~20 38217.678678
4 21~31 38879.439698date_num={}
for i in range(len(train_date)):
date=train_date['transaction_date'].iloc[i]
date_num[date]=i
date_num
{'21~29': 0, '21~28': 1, '1~10': 2, '11~20': 3, '21~31': 4, '21~30': 5}train=train.replace({'transaction_date':date_num})
test=test.replace({'transaction_date':date_num})
train.head()apartment_id city dong jibun apt exclusive_use_area year_of_completion transaction_year_month transaction_date floor transaction_real_price year month hangang day_diff
0 7622 0 335 6-13 신현(101동) 84.82 2002 200801 4 2 37500 2008 1 0 10
1 5399 0 408 142 사직파크맨션 99.17 1973 200801 2 6 20000 2008 1 0 9
2 3578 0 408 174-1 두레엘리시안 84.74 2007 200801 2 6 38500 2008 1 0 9
3 10957 0 459 95 파크팰리스 146.39 2003 200801 3 15 118000 2008 1 0 9
4 10639 0 459 110-15 킹스매너 194.43 2004 200801 4 3 120000 2008 1 0 10전처리
floor 같은 경우 음수값이 존재하기 때문에 log를 취하기 전에 각 값에 +5를 해주어 모든 값을 양수로 만들어주자.
train['floor']=np.log(train['floor']+5)
test['floor']=np.log(test['floor']+5)
f,ax=plt.subplots(figsize=(8,6))
sns.distplot(train['floor'])
print("%s->Skewness: %f, Kurtosis: %f"%('floor',train['floor'].skew(),train['floor'].kurt()))
floor->Skewness: 0.089636, Kurtosis: -0.640885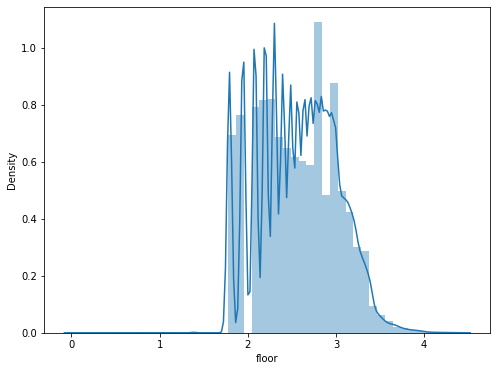
이제 아파트와 지번 그리고 거래년월을 없애버리자.
drop_columns=['apt','jibun','transaction_year_month']
train=train.drop(drop_columns,axis=1)
test=test.drop(drop_columns,axis=1)
train.head() apartment_id city dong exclusive_use_area year_of_completion transaction_date floor transaction_real_price year month hangang day_diff
0 7622 0 335 84.82 2002 4 1.945910 37500 2008 1 0 10
1 5399 0 408 99.17 1973 2 2.397895 20000 2008 1 0 9
2 3578 0 408 84.74 2007 2 2.397895 38500 2008 1 0 9
3 10957 0 459 146.39 2003 3 2.995732 118000 2008 1 0 9
4 10639 0 459 194.43 2004 4 2.079442 120000 2008 1 0 10Feature Engineering
train_test_data=[train,test]
for dataset in train_test_data:
dataset['age']=dataset['year']-dataset['year_of_completion']
dataset['is_rebuild']=(dataset['age']>=30).astype(int)
거래하는 기간까지의 아파트 나이를 특징으로 생성해주고, 샘플코드에 있는 아파트의 재건축 유무를 판단하는 특징을 만들어준다.
train_columns=[]
for column in train.columns[:]:
if train[column].skew()>=1:
print('%s -> Skewness: %f, Kurtosis: %f'%(column,train[column].skew(),train[column].kurt()))
train_columns.append(column)
elif train[column].kurt()>=3:
print('%s -->Skewness: %f, Kurtosis: %f'%(column,train[column].skew(),train[column].kurt()))
train_columns.append(column)
exclusive_use_area -> Skewness: 1.227509, Kurtosis: 3.100517
transaction_real_price -> Skewness: 3.407169, Kurtosis: 24.839821
hangang -> Skewness: 6.358349, Kurtosis: 38.428662
day_diff -->Skewness: -0.589751, Kurtosis: 4.573129
is_rebuild -> Skewness: 3.324832, Kurtosis: 9.054522정규분포 근사화를 위해 첨도와 왜도를 조정해준다.
for column in train_columns :
train[column] = np.log1p(train[column])
test[column] = np.log1p(test[column])
print("%s -> Skewness: %f, Kurtosis: %f" % (column,train[column].skew(),
train[column].kurt()))
exclusive_use_area -> Skewness: -0.438156, Kurtosis: 1.744119
hangang -> Skewness: 6.358349, Kurtosis: 38.428662
day_diff -> Skewness: -1.128137, Kurtosis: 6.788569
is_rebuild -> Skewness: 3.324832, Kurtosis: 9.054522이제 상관관계를 다시 확인해보자.
#상관관계 확인
k=train.shape[1] #히트맵 변수 갯수
corrmat = train.corr() #변수간의 상관관계
cols = corrmat.nlargest(k, 'transaction_real_price')['transaction_real_price'].index #price기준으로 제일 큰순서대로 20개를 뽑아냄
cm = np.corrcoef(train[cols].values.T)
f, ax = plt.subplots(figsize=(20, 6))
sns.heatmap(data = cm, annot=True, square=True, fmt = '.2f', linewidths=.5, cmap='Reds',
yticklabels = cols.values, xticklabels = cols.values)
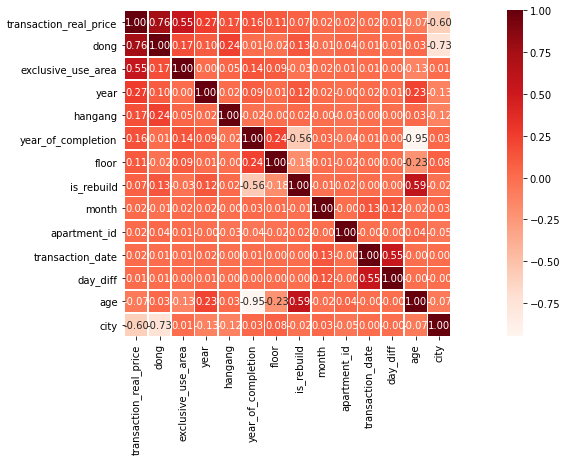
모델링
from sklearn.linear_model import ElasticNet, Lasso
from sklearn.ensemble import GradientBoostingRegressor, RandomForestRegressor
from sklearn.kernel_ridge import KernelRidge
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import RobustScaler
from sklearn.model_selection import KFold, cross_val_score, train_test_split
from sklearn.metrics import mean_squared_error
import xgboost as xgb
import lightgbm as lgbtarget = train['transaction_real_price']
del train['transaction_real_price']#cross validation score
n_folds = 2
def cv_score(models):
kfold = KFold(n_splits=n_folds, shuffle=True ,random_state=42).get_n_splits(train.values)
for m in models:
cvs = np.mean(cross_val_score(m['model'], train.values, target, cv=kfold))
rmse = np.mean(np.sqrt(-cross_val_score(m['model'], train.values, np.expm1(target), scoring = "neg_mean_squared_error", cv = kfold)))
print("Model {} CV score : {:.4f}".format(m['name'], cvs))
print("RMSE : {:.4f}".format(rmse))lasso = make_pipeline(RobustScaler(), Lasso(alpha = 0.0005, random_state=42))
ENet = make_pipeline(RobustScaler(), ElasticNet(alpha=0.0005, l1_ratio=.9, random_state=42))
gboost = GradientBoostingRegressor(random_state=42)
forest = RandomForestRegressor(n_estimators = 100, n_jobs = -1, random_state=42)
xgboost = xgb.XGBRegressor(random_state=42)
lightgbm = lgb.LGBMRegressor(random_state=42, num_leaves = 100, min_data_in_leaf = 15, max_depth=6,
learning_rate = 0.1, min_child_samples = 30, feature_fraction=0.9, bagging_freq= 1,
bagging_fraction = 0.9, bagging_seed = 11, lambda_l1 = 0.1, verbosity = -1 )
models = [{'model': gboost, 'name':'GradientBoosting'}, {'model': xgboost, 'name':'XGBoost'},
{'model': lightgbm, 'name':'LightGBM'}, {'model' : lasso, 'name' : 'LASSO Regression'},
{'model' : ENet, 'name' : 'Elastic Net Regression'}, {'model' : forest, 'name' : 'RandomForset'}]start = timeit.default_timer()
cv_score(models)
stop = timeit.default_timer()
print('불러오는데 걸린 시간 : {}초'.format(stop - start))Model GradientBoosting CV score : 0.5706
RMSE : 0.0108
Model XGBoost CV score : 0.5788
RMSE : 0.0108
Model LightGBM CV score : 0.5681
RMSE : 0.0108
Model LASSO Regression CV score : 0.5526
RMSE : 0.0107
Model Elastic Net Regression CV score : 0.5602
RMSE : 0.0106
Model RandomForset CV score : 0.4911
RMSE : 0.0118
불러오는데 걸린 시간 : 910.3417148000003초#여러개의 모델로 만들어진 predict 데이터들의 평균을 구한다.
models = [{'model':xgboost, 'name':'XGBoost'},
{'model':lightgbm, 'name':'LightGBM'},
{'model':forest, 'name' : 'RandomForest'}]
def AveragingBlending(models, x, y, sub_x):
for m in models :
m['model'].fit(x.values, y)
predictions = np.column_stack([m['model'].predict(sub_x.values) for m in models])
return predictionsstart = timeit.default_timer()
y_test_pred = AveragingBlending(models, train, target, test)
y_test_pred = (y_test_pred[:, 0]*0.05 + y_test_pred[:, 1]*0.1 + y_test_pred[:, 2]*0.85)
predictions = y_test_pred
stop = timeit.default_timer()
print('불러오는데 걸린 시간 : {}초'.format(stop - start))[LightGBM] [Warning] feature_fraction is set=0.9, colsample_bytree=1.0 will be ignored. Current value: feature_fraction=0.9
[LightGBM] [Warning] min_data_in_leaf is set=15, min_child_samples=30 will be ignored. Current value: min_data_in_leaf=15
[LightGBM] [Warning] lambda_l1 is set=0.1, reg_alpha=0.0 will be ignored. Current value: lambda_l1=0.1
[LightGBM] [Warning] bagging_fraction is set=0.9, subsample=1.0 will be ignored. Current value: bagging_fraction=0.9
[LightGBM] [Warning] bagging_freq is set=1, subsample_freq=0 will be ignored. Current value: bagging_freq=1
불러오는데 걸린 시간 : 260.0541379999995초sub = pd.read_csv('d:/data/real_estate/submission.csv')
sub['transaction_real_price'] = np.expm1(predictions)
sub.to_csv('d:/data/real_estate/submission.csv', index=False)
'Machine Learning Projects' 카테고리의 다른 글
| 청와대 청원: 청원의 주제가 무엇인가(GRU) (0) | 2021.03.12 |
|---|---|
| 청와대 청원: 청원의 주제가 무엇인가(LSTM with Original) (0) | 2021.03.12 |
| 트랜스포머를 활용한 Chatbot 만들기 (0) | 2021.03.06 |
| 간단한 이미지 분류기(Simple Image Classifier) 마동석, 김종국, 이병헌 (0) | 2021.03.03 |