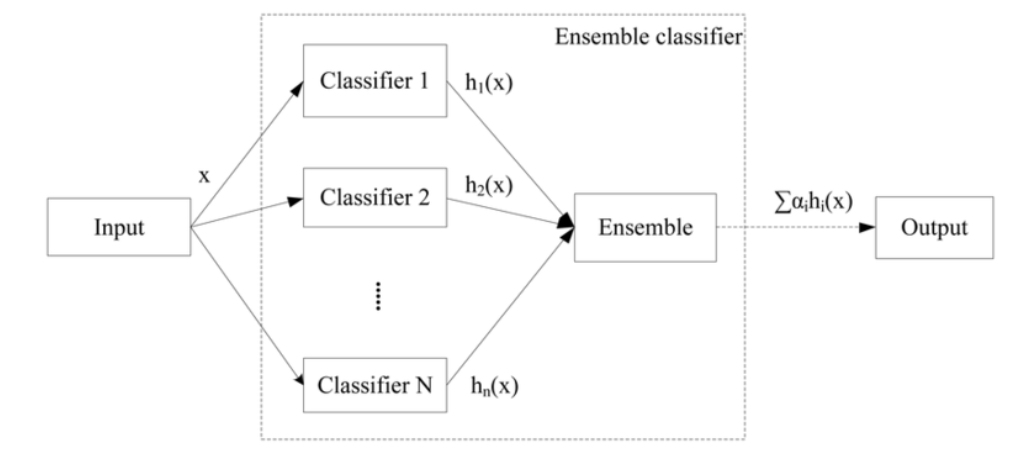
로지스틱 회귀(Logistic Regression)
영국의 통계학자인 D.R. Cox가 1958년에 자안한 확률 모델로서 독립 변수의 선형 결합을 이용하여 사건의 발생 가능성을 예측하는데 사용되는 통계 기법이다.
로지스틱 회귀의 목적은 일반적인 회귀 분석의 목표와 동일하게 종속변수와 독립변수간의 관계를 구체적인 함수로 나타내어 향후 예측 모델에 사용하는 것이다.
로지스틱 함수(Logistic Function), Odds
실제 많은 자연, 사회현상에서는 특정 변수에 대한 확률값이 선형이 아닌 S-Curve 형태를 따라는 경우가 많다.
이러한 S-Curve 함수를 표현해낸 것이 바로 로지스틱 함수이다.
이것이 인공지능 분야에서는 시그모이드 함수라고 불린다.
로지스틱 함수는 x값으로 어떤 값이든 받을 수가 있지만 출력 결과는 항상 0에서 1사이 값이 된다. 즉, 확률밀도함수(Probability Density Function, PDF)요건을 충족시키는 함수다.
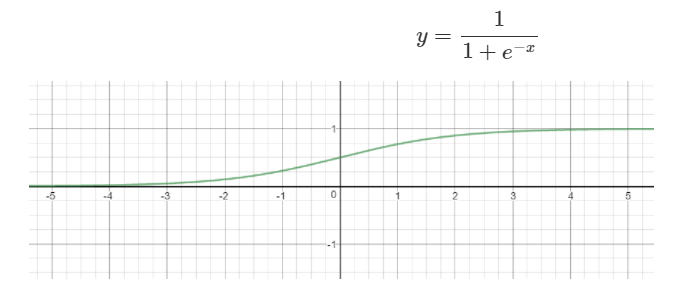 로지스틱 함수(Sigmoid)
로지스틱 함수(Sigmoid)
승산(Odds)이란 임의의 사건 A가 발생하지 않을 확률 대비 일어날 확률의 비율을 뜻한다.
 Odds
Odds
만약 사건 A가 일어날 확률 P(A)가 1에 가까워 진다면, 그 승산 값은 점점 커진다. 반대로 P(A) 가 0으로 가까워 진다면 값은 점점 작아진다는 뜻이다.
P(A)를 x축 사건, A의 승산을 y축에 놓고 그래프를 본다면 다음과 같다.

이항 로지스틱 회귀
이항 로지스틱이란 범주가 두 개인 분류 문제를 풀어야 하는 경우 사용된다. 종속 변수 Y가 연속형 숫자가 아닌 범주일 때는 기존 회귀 모델을 적용할 수 없다.
회귀식의 장점은 그대로 유지하되 종속변수 Y를 범주가 아닌(범주 1이 될)확률로 두고 식을 세워보자.

위 식에서 좌변의 범위는 0~1사이다. 하지만 우변은 음의 무한대에서 양의 무한대 범위를 가지기 때문에 식이 성립하지 않는 경우가 존재할 수 있다. 좌변을 Odds로 설정해보자.
 좌변을 Odds로
좌변을 Odds로
그러나 이번에도 범위는 맞지 않는다. 좌변의 범위는 0에서 무한대의 범위를 갖는다. 이와는 다르게 우변(회귀식)은 그대로 음의 무한대에서 양의 무한대 범위이다.
이 과정에서 로그를 취하자. 이 결과 로그 승산의 범위는 음의 무한대에서 양의 무한대가 된다. 이렇게 함으로써 양변의 범위가 일치하게 된다. 다음은 로그승산의 그래프이다.
 로그 승산 그래프
로그 승산 그래프
결과적으로 로지스틱 회귀 모델의 최종 식은 다음과 같다.

위 식을 입력벡터 x가 주어졌을 때 범주 1일 확률을 기준으로 정리해주면 다음과 같다.

최종 도출된 식은 곧 로지스틱 함수의 꼴과 같다.
이항 로지스틱 회귀의 결정경계
위와 같이 이항 로지스틱 모델에 범주 정보를 모르는 입력벡터 x를 넣으면 범주 1에 속할 확률을 반환해 준다.
그 확률값이 얼마나 되어야 범주 1로 분류할 수 있는가? 가장 간단한 방법은 다음과 같다.
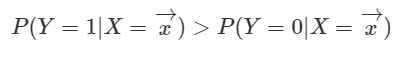
범주가 두 개뿐이므로, 위 식 좌변을 p(x)로 환하면 식을 다음과 같이 정리할 수 있다.

마찬가지로 βTx<0βTx<0 이면, 해당 데이터의 범주를 0으로 분류하게 된다. 따라서, 로지스틱모델의 결정경계(decision boundry)는 βTx=0βTx=0인 하이퍼플레인(hyperplane)이다.
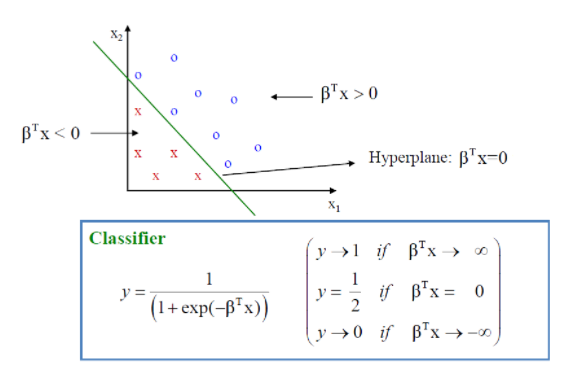 입력벡터가 2차원인 경우의 시각화
입력벡터가 2차원인 경우의 시각화
다항로지스틱 회귀
범주가 세 개 이상일때 사용한다.
그러나 범주가 3개만 있다면 이항 로지스틱 모델 2개로 문제를 해결할 수 있다.

이 경우에서 모델은 2개이고 범주가 3개인데 이 관계는 다음과 같다.

K(>=3)범주를 분류하는 다항로지스틱 회귀 모델의 입력벡터 x가 각 클래스로 분류될 확률은 다음과 같다.

위 식은 다음과 같이 이해하면 가장 쉬울 것이다. k개의 범주가 생길 확률을 전부 더한것에서 k가 일어날 확률이다.
머신러닝과 로지스틱
로지스틱회귀는 결국 이항이든 다항이든 머신러닝 분류문제를 해결하는 방법 중 하나이다.
결론적으로 위 내용은 통계학적 지식을 기반으로 이해하는 방법이며, ML 분류 문제를 다룰 경우 본인이 생각하는 가장 쉬운 2가지 방법이 있다.
<파이썬>
1. 사이킷런 LogisticRegression() 모듈 사용

Parameter
-Penalty: {'l1','l2','elasticnet','none'}, default='l2'
-dual: bool, default=False
-tol: float, default=1e-4 => 정지 기준에 대한 허용오차 설정
-C: float, default=1.0 =>정규화 강도에 대한 역, 서포트벡터 머신과 마찬가지로 값이 작을수록 더 강력한 정규화 지정
-fit_intercept: bool, default=True
-intercept_scaling: float,default=1
-class_weight: dict or 'balanced', default=None
-random_state: int, RandomState instance, default=None
-solver: {'newton-cg','lbfgs','liblinear','sag','saga'}, default='lbfgs'
-max_iter: int,default=100
-multi_class: {'auto','ovr','multinomial'},default='auto'
-verbose: int,default=0
-warm_start: bool,default=False
-n_jobs: int, default=None
-l1_ratio: float,default=None
Attributes
Class_: ndarray of shape(n_classes,)
coef_: ndarray of shape(1,n_features) or (n_classes,n_features)
intercept: ndarray of shape(1,) or (n_classes,)
n_iter_: ndarray of shape(n_classes,) or (1,)
Methods

2. tensorflow.keras.losses.categorical_crossentropy
위 모듈은 대분류에서 위 방법만을 얘기한 것 이므로 추후에 다시한번 포스팅 하겠다.