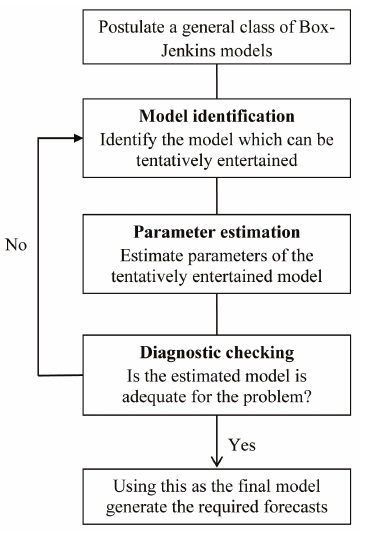
ARIMA 모형은 대표적인 통계적 시계열 예측 모형으로, 현재 값을 과거 값과 과거 예측 오차를 통해 설명한다. 이 모형을 적합하려면 시계열 Yt가 정상성 조건을 만족하는 정상 시계열(Stationary series)이어야 한다. (정확하게는 약정상성, weak stationary). 또한, 주어진 시계열 자료에 적합한 ARIMA(p,d,q)를 결정하는 절차는 Box-Jenkins method를 따르며, ACF(Autocorrelation function: 자기상관함수)로 시계열의 특성을 파악하고 적절한 차수의 ARIMA 모형을 선택한다.
정상성(Stationary)
우리는 시간의 순서에 따라 기록되지 않은 일반적 자료들을 분석할 때, Random sample들에 iid가정을 한다.
*iid: All samples are independent and identically distributed
시간에 종속되어있는 시게열은 상식적으로 iid 가정을 할 수 없다. 그래서 이러한 시계열 자료에 대해 예측 모형을 적합하고 통계적 검정을 하기 위해서는 분석을 단순화 시킬 수 있는 새로운 가정이 필요하다.
이중 가장 중요한 것이 시계열 모형의 확률적 성질이 시간에 따라 변하지 않는다고 가정하는 정상성 가정이다.
ARIMA모형은 해당 시계열이 약정상성(Weak Stationary)를 만족한다고 가정하며, 약정상성을 만족해야 좋은 fitting과 predict 성능을 보여줄 수 있다. 시계열 Yt가 다음의 세 조건을 만족할 때 약정상성을 가진다고 표현한다. 시계열 분서겡서 말하는 정상 시계열(Stationary series)은 약 정상성을 가지는 시계열을 말한다.
-평균이 모든 시점 t에서 동일하다 : 추세, 계절성, 순환성 등의 패턴이 보이지 않게 된다.
-분산이 모든 시점 t에서 동일하다: 자료 변화의 폭이 일정하게 된다.
-Yt와 Y(t-h) 간의 Covariation(즉, Yt의 자기 공분산 함수)이 모든 시점 t에 대해서 동일하다: 시간에 따라 상이한 자기상관적 패턴을 보이지 않게 된다.
즉, 풀어설명하자면 추세와 계절성이 있는 시계열은 정상성을 나타내는 시계열이 아니다. 일반적으로 정상성을 나타내는 시계열은 장기적으로 볼 때 예측할 수 있는 패턴을 나타내지 않을 것이다. (어떤 주기적인 행동이 있을 수 있더라도) 시간 그래프는 시계열이 일정한 분산을 갖고 대략적으로 평평하게 될 것을 나타낼 것이다.

그렇다면 다음 시계열 그래프중 어떤 것이 정상성을 나타낼까?
a) 거래일 200일 동안의 구글 주식 가격
b) 거래일 200일 동안의 구글 주식 가격의 일일 변동
c) 미국의 연간 파업 수
d) 미국에서 판매되는 새로운 단독 주택의 월별 판매액
e) 미국에서 계란 12개의 연간 가격(고정 달러)
f) 호주 빅토리아 주에서 매월 도살한 돼지의 전체 수
g) 캐나다 북서부 맥킨지 강 지역에서 연간 포획된 시라소니의 전체 수
h) 호주 월별 맥주 생산량
i) 호주 월별 전기 생산량
분명하게 계절성이 보이는 d),h),i)는 후보가 되지 못한다. 추세가 있고 수준이 변하는 a),c),e),f),i)도 후보가 되지 못한다. 분산이 증가하는 i)도 후보가 되지 못한다. 그렇다면 b)와 g)만 정상성을 나타내는 시계열 후보로 남았다.
얼핏 보면 시계열 g)에서 나타나는 뚜렷한 주기(cycle)때문에 정상성을 나타내는 시계열이 아닌 것처럼 보일 수 있다. 하지만 이러한 주기는 불규칙적(aperiodic)이다.
즉, 먹이를 구하기 힘들만큼 시라소니 개체수가 너무 많이 늘어나 번식을 멈춰서, 개체수가 작은 숫자로 줄어들고, 그 다음 먹이를 구할 수 있게 되어 개체수가 다시 늘어나는 식이다.
장기적으로 볼 때 , 이러한 주기의 시작이나 끝은 예측할 수 없다. 따라서 이 시계열은 정상성을 나타내느 시계열이다.
차분(differencing)

처음 그림에서 패널(a) 의 구글 주식 가격이 정상성을 나타내는 시계열이 아니었지만 (b)의 일별 변화는 정상성을 나타냈다느 것에 주목해보자. 이 그림은 정상성을 나타내지 않는 시계열을 정상성을 나타내도록 만드는 한 가지 방법을 나타낸다.
연이은 관측값들의 차이를 계산하는 것이다. 이를 차분(differencing)이라 부른다.
로그변환은 시계열의 분산 변화를 일정하게 만드는데 도움이 될 수 있다. 차분(differencing)은 시계열의 수준에서 나타내느 변화를 제거하여 시계열의 평균 변화를 일정하게 만드는데 도움이 될 수 있다. 결과적으로 추세나 계절성이 제거(또는 감소) 된다.
정상성을 나타내지 않는 시계열을 찾아낼 때 데이터의 시간 그래프를 살펴보는 것만큼, ACF 그래프도 유용하다. 정상성을 나타내지 않는 데이터에서는 ACF가 느리게 감소하지만, 정상성을 나타내는 시계열에서는, ACF가 비교적 빠르게 0으로 떨어질 것이다. 그리고 정상성을 나타내지 않는 데이터에서 r1은 종종 큰 양수 값을 갖는다.
차분을 구한 구글 주식 가격의 ACF는 단순히 white noise 시계열처럼 생겼다. 95% limitation 바깥에 자기상관(autocorrelation)값이 없고, 융-박스(Ljung-Box) Q* 통계는 h=10 에 대해 0.355라는 p-value를 갖는다. 이 결과는 구글 주식 가격의 일별
Box.test(diff(goog200), lag=10, type="LJung-Box")
#Box-Ljung test
#data: diff(goog200)
#X-Squared=11, df=10, p-value=0.4변동이 기본적으로는 이전 거래일의 데이터와 상관이 없는 무작위적인 양이라는 것을 말해준다.
확률보행 모델
차분(difference)을 구한 시게열은 원래의 시계열에서 연이은 관측값의 차이이고, 다음과 같이 쓸 수 있다.

첫 번째 관측값에 대한 차분 y'1을 계산할 수 없기 때문에 차분을 구한 시계열은 T-1개의 값만 가질 것이다.
차분을 구한 시계열이 white noise이면, 원래 시계열에 대한 모델은 다음과 같이 쓸 수 있다.

여기서 Error(t)는 white noise를 의미한다. 이것을 정리하면 '확률보행(random walk)' 모델을 얻는다.

확률보행(random walk) 모델은 정상성을 나타내지 않은 데이터, 특별히 금융이나 경제 데이터를 다룰 때 널리 사용되고 있다. 확률보행에는 보통 다음과 같은 특징을 가진다.
-누가 봐도 알 수 있는 긴 주기를 갖는 상향 또는 하향 추세가 있다.
-갑작스럽고 예측할 수 없는 방향 변화가 있다.
미래 이동을 예측할 수 없고 위로 갈 확률이나 아래로 갈 확률이 정확하게 같기 때문에 확률보행 모델에서 얻어낸 예측값은 마지막 관측값과 같다. 따라서, 확률보행 모델은 단순(naive) 예측값을 뒷받침한다.
밀접하게 연관된 모델은 차분값이 0이 아닌 평균값을 갖게 한다. 그러면,

c값은 연이은 관측값의 차이의 평균이다. c가 양수이면, 평균 변화는 y(t)값에 따라 증가한다. 따라서 y(t)는 위쪽 방향으로 이동하는 경향을 나타낼 것이다. 하지만 c가 음수이면, y(t)는 아래쪽 방향으로 이동하는 경향을 나타낼 것이다.
2차 차분
가끔 차분(difference)을 구한 데이터가 정상성(stationarity)이 없다고 보일 수도 있다. 정상성을 나타내는 시계열을 얻기 위해 데이터에서 다음과 같이 한 번 더 차분을 구하는 작업이 필요할 수 있다.

이 경우에는, y(t)''는 T-2개의 값을 가질 것이다. 그러면, 원본 데이터의 '변화에서 나타나는 변화'를 모델링하게 되는 셈이다. 실제 상황에서는, 2차 차분 이상으로 구해야 하는 경우는 거의 일어나지 않는다.
계절성 차분
계절성 차분(seasonal differencing)은 관측치와, 같은 계절의 이전 관측값과의 차이를 말한다. 따라서

여기에서 m은 계절의 개수이다. m 주기 시차 뒤의 관측을 빼기 때문에 시차 m 차분이라고 부르기도 한다.
계절성으로 차분을 구한 데이터가 white nois로 보이면, 원본 데이터에 대해 적절한 모델은 다음과 같다.

이 모델에서 낸 예측값은 관련 있느 계절의 마지막 관측값과 같다. 즉, 이 모델은 계절성 단순(seasonal naive) 예측값을 나타낸다.
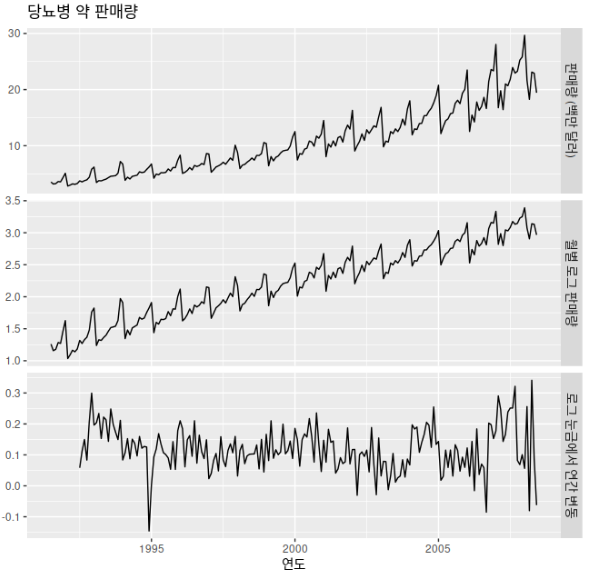
위 그림의 아래쪽 패널은 호주에서 팔린 A10 약물(당뇨병 약)의 월별 처방전의 수에 로그를 취하여 계절성 차분을 구한 결과를 나타낸다. 변환과 차분을 통해 시계열이 정상성을 나타내는 것처럼 보인다.
cbind("판매량 (백만 달러)"= a10,
"월별 로그 판매량"= log(a10),
"로그 눈금에서 연간 변동"=diff(log(a10),12))%>%
autoplot(facets=TRUE)+
xlab("연도")+ylab("")+
ggtitle("당뇨병 약 판매량")보통의 차분과 계절성 차분을 구분하기 위해, 때때로 보통의 차분을 시차 1에서 차분을 구한다는 의미로 "1차 차분(first difference)"라고 부른다.

위 그림에서 나타낸 것처럼, 계절성을 나타내는 데이터를 얻기 위해 계절성 차분과 1차 차분 둘 다 구하는 것이 필요하기도 한다. 여기서는 데이터를 먼저 로그로 변환하고(두번째 패널), 그 후 계절성 차분을 계산했다(세번째 패널). 데이터에서 여전히 정상성이 보이지 않는 것 같아서, 1차 차분을 더 많이 계산했다.
cbind("10억 kWh" = usmelec,
"로그" = log(usmelec),
"계절성\n 차분 로그값" =
diff(log(usmelec),12),
"두 번\n 차분을 구한 로그값" =
diff(diff(log(usmelec),12),1)) %>%
autoplot(facets=TRUE) +
xlab("연도") + ylab("") +
ggtitle("미국 월별 순 전기 생산량")
어떤 차분(difference)을 구할지 정할 때는 주관적인 요소가 어느정도 들어간다. 위 약물 그림의 계절성 차분(seasonal difference)을 구한 데이터는 월별 순 전기 생산량의 계절성 차분을 구한 데이터와는 큰 차이를 나타내지 않는다. 후자의 경우, 계절성 차분을 구한 데이터로 결정했어야 했고, 차분을 더 구하지 않아도 되었다. 이에 반면해 전자의 경우에는 데이터의 정상성(stationarity)이 충분히 나타나지 않아서 차분을 더 구해야 했다. 차분을 구하는 것에 대한 몇가지 형식적인 검정을 아래에서 다루지만, 모델링 과정에서 항상 몇 가지 선택이 존재하고, 분석하는 사람마다 다른 선택을 할 수 있다.
y'(t)=y(t)-y(t-m)가 계절성 차분(seasonal difference)을 구한 시계열을 나타낸다면, 두 번 차분한 시계열은 다음과 같다.

계절성 차분과 1차 차분을 둘 다 적용할 때, 어떤 것을 먼저 적용하더라도 차이는 없다. 결과는 같을 것이다. 하지만, 데이터에 계절성 패턴이 강하게 나타나면, 계절성 차분을 먼저 계산하는 것을 추천한다. 왜냐면, 때때로 결과 시계열에서 정상성이 나타나기도 해서 이런 경우 1차 차분을 구할 필요가 없게 되기 때문이다. 1차 차분을 먼저 계산했다면, 여전히 남아있는 계절성이 나타날 것이다.
차분을 구했다면, 차분 값이 해석 가능할 것이라는 것은 중요하다. 첫 번째 차분값은 한 관측값과 그 다음 관측값 사이의 변화이다. 계절성 차분값은 한 해와 그 다음 해 사이의 변화이다. 다른 시차값(lagged value)은 직관적으로 해석하기가 쉽지 않기 때문에 사용하지 않는 것이 좋다.
단위근검정
단위근검정(unit root tests)은 더 객관적으로 차분을 구하는 것이 필요할 지 결정하기 위해 사용하는 한 가지 방법이다. 차분을 구하는 것이 필요한지 결정하는 상황을 위해 설계된 통계적 가설 검정들이 존재한다. 사용할 수 있는 단위근검정은 다양하고, 서로 다른 가정에 기초하고 있으며, 상반되는 답을 낼 수도 있다. 분석 과정에서 KPSS(Kwiatkowski-Phillips-Schmidt-Shin)검정을 사용한다. 이 검정은 데이터에 정상성이 나타난다는 것이 귀무가설이고, 귀무 가설이 거짓이라는 증거를 찾으려고 한다. 결과적으로 ,작은 p-value는 차이를 구하는 것이 필요하다는 것을 나타낸다. 검정은 다음과 같다.
예로는 구글 주식 가격 데이터에 적용해보자.
library(urca)
goog %>% ur.kpss() %>% summary()
#>
#> #######################
#> # KPSS Unit Root Test #
#> #######################
#>
#> Test is of type: mu with 7 lags.
#>
#> Value of test-statistic is: 10.72
#>
#> Critical value for a significance level of:
#> 10pct 5pct 2.5pct 1pct
#> critical values 0.347 0.463 0.574 0.739검정 통계량은 1% 임계값보다 훨씬 크다. 이것은 귀무가설이 기각 된다는 것을 의미한다. 즉, 데이터가 정상성을 가지고 있지 않다. 데이터에 차분을 수행할 수 있고 검정을 다시 적용할 수 있다.
goog %>% diff() %>% ur.kpss() %>% summary()
#>
#> #######################
#> # KPSS Unit Root Test #
#> #######################
#>
#> Test is of type: mu with 7 lags.
#>
#> Value of test-statistic is: 0.0324
#>
#> Critical value for a significance level of:
#> 10pct 5pct 2.5pct 1pct
#> critical values 0.347 0.463 0.574 0.739이번에는 검정 통계가 작고(0.0324), 정상성이 나타나는 데이터에서 볼 수 있는 것처럼 범위 안에 잘 들어간다. 따라서 차분을 구한 데이터가 정상성을 나타낸다고 결론내릴 수 있다.
1차 차분의 적당한 횟수를 결정하기 위해 여러번의 KPSS 검정을 사용하는 이 과정을 ndiffs()로 수행할 수 있다.
ndiffs(goog)
#> [1] 1위 검정들에서 본 것처럼, google데이터가 정상성을 나타내도록 하려면 한번의 차분(difference)이 필요하다.
계절성 차분(seasonal difference)이 필요한지 결정하기 위한 비슷한 함수는 nsdiffs()이다. 이 함수는 필요한 계절성 차분의 적당한 횟수를 결정하기 위해 계절성 강도 측정량을 사용한다. Fs<0.64이면, 계절성 차분이 필요 없다고 알려주고, 이외의 경우에는 하나의 계절성 차분이 필요하다 알려준다.
'Deep Learning > Time-Series' 카테고리의 다른 글
| 2. Auto-regressive Integrated Moving Average (ARIMA) 모형(비-계절성 ARIMA 모델) (0) | 2021.03.25 |
|---|---|
| 2. Auto-regressive Integrated Moving Average (ARIMA) 모형(이동 평균 모델) (0) | 2021.03.22 |
| 2. Auto-regressive Integrated Moving Average (ARIMA) 모형(자기회귀 모델) (0) | 2021.03.22 |
| 2. Auto-regressive Integrated Moving Average (ARIMA) 모형(후방이동 기호) (0) | 2021.03.21 |
| 1. 시계열 예측이란? (0) | 2021.03.21 |