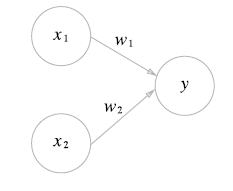
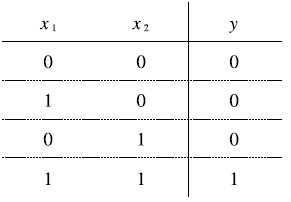
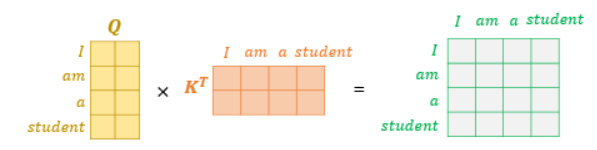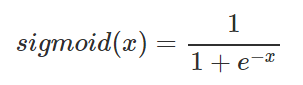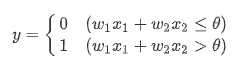2021/03/04 - [Deep Learning/Deep Leaning inside] - 트랜스포머(Transformer)(1)
8)패딩 마스크(Padding Mask)
앞서 포스팅한 Scaled dot-product attention함수 내부를 보면 mask라는 값을 인자로 받아서, 이 mask값에다가 -1e9라는 아주 작은 음수값을 곱한 후 어텐션 스코어 행렬에 더해준다.
이는 입력 문장에 <PAD>토큰이 있을 경우 어텐션에서 사실상 제외하기 위한 연산이다.
그림을 통해 이해해보자.

사실 단어 <PAD>의 경우에는 실질적인 의미를 가진 단어가 아니다. 그렇기에 트랜스포머에서는 Key의 경우에 <PAD> 토큰이 존재한다면 이에 대해 유사도를 구하지 않도록 마스킹을 해주기로 했다.
*masking이란 어텐션에서 제외하기 위해 값을 가린다는 의미이다.
어텐션 스코어 행렬에서 행에 해당하는 문장은 Query, 열에 해당하는 문장은 Key이다. 그리고 Key에 <PAD>가 있는 경우에는 해당 열 전체를 masking 해준다.
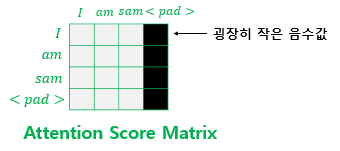
masking하는 방법은 어텐션 스코어 행렬의 마스킹 위치에 매우 작은 음수값을 넣어주는 것이다. 현재 어텐션 스코어 함수는 소프트맥스 함수를 지나지 않은 상태이다. 현재 마스킹 위치에 매우 작은 음수 값이 들어가 있으므로 어텐션 스코어 행렬이 소프트맥스 함수를 지난 후에는 해당 위치의 값은 0에 근사한 값을 갖게 되어 단어간 유사도를 구하는 일에 <PAD> 토큰은 반영되지 않는다는 의미이다.
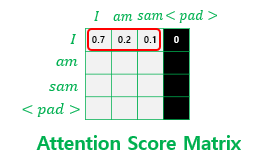
위 그림은 소프트맥스 함수를 지난 후의 그림이다. 각 행의 어텐션 가중치는 총합 1이 되는데, <PAD>의 경우 0이되어 어떤 값도 갖고 있지 않다.
패딩마스크를 구현하는 방법은 입력된 정수 시퀀스에서 패딩 토큰의 인덱스인지, 아닌지를 판별하는 함수를 구현하는 것이다.
def create_padding_mask(x):
mask=tf.cast(tf.math.equal(x,0),tf.float32)
return mask[:,tf.newaxis,tf.newaxis,:]
print(create_padding_mask(tf.constant([[1,21,777,0,0]])))
tf.Tensor([[[[0. 0. 0. 1. 1.]]]], shape=(1, 1, 1, 5), dtype=float32)위 함수는 정수 시퀀스에서 패딩 토큰의 인덱스인지 아닌지를 판별하는 함수이다.
0인경우에는 1로 변환하고, 그렇지 않은경우에는 0으로 변환하는 함수이다.
결과를 살펴보면 위 벡터를 통해서 1의 값을 가진 위치의 열을 어텐션 스코어 행렬에서 마스킹하는 용도로 사용할 수 있다. 위 벡터를 Scaled dot-product attention 인자로 전달하면, scaled dot-product attention에는 매우 작은 음수값인 -1e9를 곱하고 이를 행렬에 더해주어 해당 열을 전부 마스킹하게 되는 것이다.
포지션-와이즈 피드 포워드 신경망(Position-wise FFNN)
포지션-와이즈 FFNN는 쉽게 말하면 완전 연결(Fully-connected FFNN)이라고 해석할 수 있다. 다음 수식을 살펴보자.
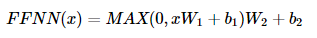

-x는 앞서 멀티 헤드 어텐션의 결과로 나온(seq_len,d(model))의 크기를 가지는 행렬을 말한다. 가중치 행렬 W1은 (d(model),d(ff))의 크기를 가지고, 가중치 행렬 W2는 (d(ff),d(model))의 크기를 가진다.
*논문에서는 은닉층의 크기인 d(ff)는 2047의 크기를 가진다.
여기서 매개변수 W1,b1,W2,b2는 하나의 인코더 층 내에서는 다른 문장, 다른 단어들마다 정확하게 동일하게 사용된다. 하지만 인코더 층마다 다른 값을 가진다.
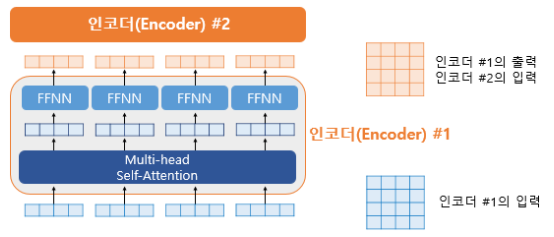
위 그림에서 좌측은 인코더의 입력을 벡터 단위로 봤을 떄, 각 벡터들이 멀티헤드 어텐션 층이라는 인코더 내 첫번째 서브 층을 지나, FFNN을 통과하는 과정을 보여준다.
위 그림을 코딩으로 구현해보자.
outputs=tf.keras.layers.Dense(units=dff,activation='relu')(attention)
outputs=tf.keras.layers.Dense(units=d_model)(outputs)잔차 연결(Residual connection)과 층 정규화(Layer Normalization)
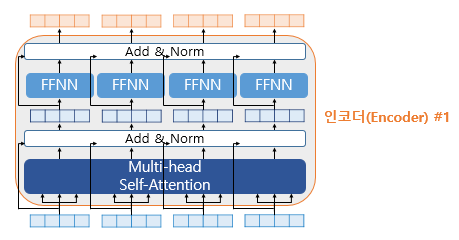
트랜스포머에서는 위 그림처럼 두 개의 서브층을 가진 인코더에 추가적으로 사용하는 기법이 있다.
바로 Add&Norm이다. 더 정확히는 이를 잔차 연결(residual connection) 과 층 정규화(layer nomalization)이라 부른다.
1)잔차 연결(Residual connection)
다음 식을 확인해보자.

위 그림은 입력 x와 x에 대한 어떤 함수 F(x)의 값을 더한 H(x)의 구조를 보여준다. 여기서 F(x)는 트랜스포머에서 서브층에 해당된다. 다시 말해 잔차 연결은 서브층의 입력과 출력을 더하는 것을 말한다.
위에서 언급했듯이 서브층의 입력과 출력은 동일한 차원을 갖고 있으므로, 서브층의 입력과 서브층의 출력은 연산을 할 수 있다.
2)층 정규화(Layer Normalization)
잔차 연결을 거친 결과는 이어, 층 정규화 과정을 거친다. 잔차 연결의 입력을 x, 잔차 연결과 층 정규화 두 가지 연산을 모두 수행한 후의 결과 행렬을 LN이라 하였을 때, 잔차 연결 후 층 정규화 연산을 수식으로 표현하면 다음과 같다.
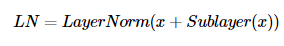
층 정규화란 텐서의 마지막 차원에 대해서 평균과 분산을 구하고, 이를 가지고 어떤 수식을 통해 값을 정규화하여 학습을 돕는다.
*텐서의 마지막 차원이란 트랜스포머에서는 d(model)차원을 의미한다.
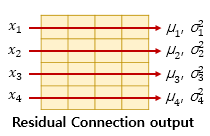
층 정규화를 수행한 후에는 벡터 x(i)는 ln(i) 라는 벡터로 정규화가 된다.

수식을 이해해보자. 과정은 다음과 같다.
1. 평균과 분산을 통한 정규화
2. 감마와 베타 도입
우선,평균과 분사을 통해 벡터 x(i)를 정규화 해준다. x(i)는 벡터인 반면, 평균과 분산은 스칼라이다. 벡터 xi의 각 차원을 k라고 하였을 때, x(i,k)는 다음과 같이 정규화 할 수있다.
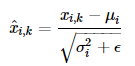
여기서 입실론은 분모가 0이되는 것을 방지하는 값이다.
γ(감마)와 β(베타) 벡터를 준비하자. 이들의 초깃값은 각각 1,0이다.

γ와 β를 도입한 층 정규화의 최종수식은 다음과 같다. γ와 β는 학습 가능한 파라미터이다.

인코더 구현하기
코딩을 살펴보자
def encoder_layer(dff,d_model,num_heads,dropout,name='encoder_layer'):
inputs=tf.keras.Input(shape=(None,d_model),name='inputs')
#인코더는 패딩 마스크 사용
padding_mask=tf.keras.Input(shape=(1,1,None),name='padding_mask')
#멀티-헤드 어텐션(첫번째 서브층/셀프 어텐션)
attention=MultiHeadAttention(d_model,num_heads,name='attention')({'query':inputs,'key':inputs,'value':inputs,'mask':padding_mask})
#드롭아웃+잔차 연결과 층 정규화
attention=tf.keras.layers.Dropout(rate=dropout)(attention)
attention=tf.keras.layers.LayerNormalization(epsilon=1e-6)(inputs+attention)
#포지션 와이즈 피드 포워드 신경망(두번째 서브층)
outputs=tf.keras.layers.Dense(units=dff,activation='relu')(attention)
outputs=tf.keras.layers.Dense(units=d_model)(outputs)
#드롭아웃+잔차 연결과 층 정규화
outputs=tf.keras.layers.Dropout(rate=dropout)(outputs)
outputs=tf.keras.layers.LayerNormalization(epsilon=1e-6)(attention+outputs)
return tf.keras.Model(inputs=[inputs,padding_mask],outputs=outputs,name=name)
인코더의 입력으로 들어가는 문장에는 패딩이 있을 수 있으므로, 어텐션 시 패딩 토큰을 제외하도록 패딩 마스크를 사용한다. 이는 MultiHeadAttention 함수의 mask의 인자값으로 padding_mask가 들어가는 이유이다.
인코더는 총 두 개의 서브층으로 이루어지는데, 멀티 헤드 어텐션과 피드 포워드 신경망이다. 각 서브층 이후에는 드롭 아웃, 잔차 연결과 층 정규화가 수행된다.
인코더 쌓기
인코더 층의 내부 아키텍처에 대해서 이해해보았다. 이러한 인코더 층을 num_layers개만큼 쌓고, 마지막 인코더 층에서 얻는 (seq_len,d_model)크기의 행렬을 디코더로 보내서 트랜스포머 인코더의 인코딩 연산이 끝나게 된다.
다음 코드는 인코더 층을 num_layers개만큼 쌓는 코드이다.
def encoder(vocab_size,num_layers,dff,d_model,num_heads,dropout,name='encoder'):
inputs=tf.keras.Input(shape=(None,),name='inputs')
#인코더는 패딩 마스크 사용
padding_mask=tf.keras.Input(shape=(1,1,None),name='padding_mask')
#포지셔널 인코딩+드롭아웃
embeddings=tf.keras.layers.Embedding(vocab_size,d_model)(inputs)
embeddings*=tf.math.sqrt(tf.cast(d_model,tf.float32))
embeddings=PositionalEncoding(vocab_size,d_model)(embeddings)
outputs=tf.keras.layers.Dropout(rate=dropout)(embeddings)
#인코더를 num_layers개 쌓기
for i in range(num_layers):
outputs=encoder_layer(dff=dff,d_model=d_model,num_heads=num_heads,dropout=dropout,name='encoder_layer_{}'.format(i),)([outputs,padding_mask])
return tf.keras.Model(inputs=[inputs,padding_mask],outputs=outputs,name=name)
인코더에서 디코더로(From Encoder To Decoder)

앞서 인코더는 총 num_layers만큼의 층 연산을 순차적으로 처리한 후, 마지막 층의 인코더의 출력을 디코더에 전달해준다. 인코더 연산이 끝났으므로, 디코더 연산이 시작되어 다시 디코더 또한 num_layers만큼의 연산을 한다.
이때마다, 인코더가 보낸 출력을 각 디코더 층 연산에 사용한다.
디코더의 첫번째 서브층: 셀프 어텐션과 룩 어헤드 마스크

위 그림과 같이 디코더도 동일하게 임베딩 층과 포지셔널 인코딩을 거친 후의 문장 행렬이 입력된다.
트랜스포머 또한 seq2seq와 마찬가지로 교사 강요(Teacher Forcing)을 사용하여 훈련되므로 학습 과정에서 디코더는 번역할 문장에 해당되는 <sos> je suis etudiant의 문장 행렬을 한 번에 입력받는다. 그 후, 디코더는 이 문장 행렬로부터 각 시점의 단어를 예측하도록 훈련된다.
<문제점>
seq2seq의 디코더에 사용되는 RNN 계열의 신경망은 입력 단어를 매 시점마다 순차적으로 받으므로 다음 단어 예측에 현재 시점 이전에 입력된 단어들만 참고 할 수 있다.
이에 반해, 트랜스포머는 문장 행렬로 입력을 한번에 받으므로 현재 시점의 단오를 예측하고자 할 떄, 입력 문장 행렬로부터 미래시점의 단어까지도 참고할 수 있는 현상이 발생한다.
이 문제점을 해결하기 위해 트랜스포머의 디코더에서는 현재 시점의 예측에서 현재 시점보다 미래에 있는 단어들을 참고하지 못하도록 룩어헤드 마스크를 도입했다.

룩어헤드 마스크(look ahead mask)는 디코더의 첫번째 서브층에서 이루어진다.
디코더의 첫번째 서브층인 멀티 헤드 셀프어텐션층은 인코더의 첫번째 서브층인 멀티 헤드 셀프 어텐션 층과 동일한 연산을 한다. 차이점은 마스킹을 적용한다는 점이다.

위 그림과 같이 셀프 어텐션을 통해 어텐션 스코어 행렬을 얻는다.
이후 자기 자신보다 미래에 있는 단어들은 참고하지 못하도록 마스킹 처리한다.
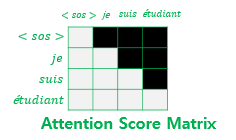
마스킹 된 후의 어텐션 스코어 행렬의 각 행을 보면 자기 자신과 그 이전 단어들만을 참고할 수 있음을 볼 수있다.
그 외에는 인코더의 첫 번째 서브층과 같다.
룩어헤드 마스크의 구현을 알아보면 패딩마스크와 마찬가지로 앞서 구현한 스케일드 닷 프로덕트 어텐션 함수에 mask라는 인자로 전달된다. 패딩 마스크를 써야하는 경우, 스케일드 닷 프로덕트 어텐션 함수에 패딩 마스크를 전달하고, 룩어헤드 마스킹을 써야 하는 경우에는 스케일드 닷 프로덕트 어텐션 함수에 룩어헤드 마스크를 전달하게 된다.
트랜스포머에는 총 3가지 어텐션이 존재한다. 모두 멀티 헤드 어텐션을 수행하고, 멀티 헤드 어텐션 함수 내부에서 스케일드 닷 프로덕트 어텐션 함수를 호출하는데 각 어텐션 시 함수에 전달하는 마스킹은 다음과 같다.
-인코더의 셀프 어텐션: 패딩마스크 전달
-디코더의 첫번째 서브층인 마스크드 셀프 어텐션: 룩어헤드 마스크를 전달
-디코더의 두번째 서브층인 인코더-디코더 어텐션: 패딩 마스크를 전달
이때, 룩어헤드 마스크를 한다고 해서 패딩 마스크가 불필요한 것이 아니므로 룩어헤드 마스크는 패딩 마스크를 포함할 수 있도록 구현한다.
#디코더의 첫번쨰 서브층(sublayer)에서 미래 토큰을 Mask하는 함수
def create_look_ahead_mask(x):
seq_len=tf.shape(x)[1]
look_ahead_mask=1-tf.linalg.band_part(tf.ones((seq_len,seq_len)),-1,0)
padding_mask=create_padding_mask(x)
return tf.maximum(look_ahead_mask,padding_mask)
print(create_look_ahead_mask(tf.constant([[1,2,0,4,5]])))
tf.Tensor(
[[[[0. 1. 1. 1. 1.]
[0. 0. 1. 1. 1.]
[0. 0. 1. 1. 1.]
[0. 0. 1. 0. 1.]
[0. 0. 1. 0. 0.]]]], shape=(1, 1, 5, 5), dtype=float32)룩어헤드 마스크이므로 삼각형 모양의 마스킹이 형성되면서, 패딩 마스크가 포함되어져 있으므로 세번째 열이 마스킹 되었다.
디코더의 두번째 서브층: 인코더 디코더 어텐션
디코더의 두번째 서브층은 멀티 헤드 어텐션을 수행한다는 점에서는 이전의 어텐션들과 같지만, 셀프 어텐션은 아니다.
셀프 어텐션은 Query,Key,Value가 같은 경우를 말하는데, 인코더-디코더 어텐션은 Query가 디코더인 행렬인 반면, Key와 Value는 인코더 행렬이기 때문이다.
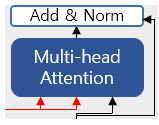
디코더의 두번째 서브층을 확대해보면, 위와 같은 그림이다.
두 개의 (빨간)화살표는 각각 Key,Value를 의미하며, 이는 인코더의 마지막 층에서 온 행렬로부터 얻는다.
반면, Query는 디코더의 첫번쨰 서브층의 결과 행렬로부터 얻는다는 점이 다르다.
Query가 디코더 행렬, Key가 인코더 행렬일 때, 어텐션 스코어 행렬을 구하는 과정은 아래 그림과 같다.

디코더 구현하기
우선 코딩을 살펴보자.
def decoder_layer(dff,d_model,num_heads,dropout,name='decoder_layer'):
inputs=tf.keras.Input(shape=(None,d_model),name='inputs')
enc_outputs=tf.keras.Input(shape=(None,d_model),name='encoder_outputs')
#룩어헤드 마스크(첫번째 서브층)
look_ahead_mask=tf.keras.Input(shape=(1,None,None),name='look_ahead_mask')
#패딩 마스크(두번째 서브층)
padding_mask=tf.keras.Input(shape=(1,1,None),name='padding_mask')
#멀티-헤드 어텐션(첫번째 서브층/마스크드 셀프 어텐션)
attention1=MultiHeadAttention(d_model,num_heads,name='attention_1')(inputs={'query':inputs,'key':inputs,'value':inputs,'mask':look_ahead_mask})
#잔차 연결과 층 정규화
attention1=tf.keras.layers.LayerNormalization(epsilon=1e-6)(attention1+inputs)
#멀티-헤드 어텐션(두번째 서브층/디코더-인코더 어텐션)
attention2=MultiHeadAttention(d_model,num_heads,name='attention_2')(inputs={'query':attention1,'key':enc_outputs,'value':enc_outputs,'mask':padding_mask})
#드롭아웃+잔차 연결과 층 정규화
attention2=tf.keras.layers.Dropout(rate=dropout)(attention2)
attention2=tf.keras.layers.LayerNormalization(epsilon=1e-6)(attention2+attention1)
#포지션 와이즈 피드 포워드 신경망(세번째 서브층)
outputs=tf.keras.layers.Dense(units=dff,activation='relu')(attention2)
outputs=tf.keras.layers.Dense(units=d_model)(outputs)
#드롭아웃+잔차 연결과 층 정규화
outputs=tf.keras.layers.Dropout(rate=dropout)(outputs)
outputs=tf.keras.layers.LayerNormalization(epsilon=1e-6)(outputs+attention2)
return tf.keras.Model(inputs=[inputs,enc_outputs,look_ahead_mask,padding_mask],outputs=outputs,name=name)
디코더는 총 세개의 서브층으로 구성된다. 첫번째와 두번째 서브층 모두 멀티 헤드 어텐션이지만, 첫번째 서브층은 mask의 인자값으로 look_ahead_mask가 들어간다.
반면, 두번째 서브층은 mask의 인자값으로 padding_mask가 들어가는 것을 확인할 수 있다.
이유는 첫번째 서브층은 마스크드 셀프 어텐션을 수행하기 때문이다. 세개의 서브층 모두 서브층 연산 후에는 드롭 아웃, 잔차 연결, 층 정규화가 수행되는 것을 알 수 있다.
디코더 쌓기
def decoder(vocab_size,num_layers,dff,d_model,num_heads,dropout,name='decoder'):
inputs=tf.keras.Input(shape=(None,),name='inputs')
enc_outputs=tf.keras.Input(shape=(None,d_model),name='encoder_outputs')
#디코더는 룩어헤드 마스크(첫번째 서브층)와 패딩 마스크(두번째 서브층) 둘 다 사용.
look_ahead_mask=tf.keras.Input(shape=(1,None,None),name='look_ahead_mask')
padding_mask=tf.keras.Input(shape=(1,1,None),name='padding_mask')
#포지셔널 인코딩 +드롭아웃
embeddings=tf.keras.layers.Embedding(vocab_size,d_model)(inputs)
embeddings*=tf.math.sqrt(tf.cast(d_model,tf.float32))
embeddings=PositionalEncoding(vocab_size,d_model)(embeddings)
outputs=tf.keras.layers.Dropout(rate=dropout)(embeddings)
#디코더를 num_layers개 쌓기
for i in range(num_layers):
outputs=decoder_layer(dff=dff,d_model=d_model,num_heads=num_heads,dropout=dropout,name='decoder_layer_{}'.format(i),)(inputs=[outputs,enc_outputs,look_ahead_mask,padding_mask])
return tf.keras.Model(inputs=[inputs,enc_outputs,look_ahead_mask,padding_mask],outputs=outputs,name=name)
이 또한 앞선 인코더 쌓기와 동일하다.
트랜스포머 전체 구현하기
def transformer(vocab_size,num_layers,dff,d_model,num_heads,dropout,name='transformer'):
#인코더 입력
inputs=tf.keras.Input(shape=(None,),name='inputs')
#디코더 입력
dec_inputs=tf.keras.Input(shape=(None,),name='dec_inputs')
#인코더의 패딩 마스크
enc_padding_mask=tf.keras.layers.Lambda(create_padding_mask,output_shape=(1,1,None),name='enc_padding_mask')(inputs)
#디코더의 룩어헤드 마스크(첫번째 서브층)
look_ahead_mask=tf.keras.layers.Lambda(create_look_ahead_mask,output_shape=(1,None,None),name='look_ahead_mask')(dec_inputs)
#디코더의 패딩 마스크(두번째 서브층)
dec_padding_mask=tf.keras.layers.Lambda(create_padding_mask,output_shape=(1,1,None),name='dec_padding_mask')(inputs)
#인코더의 출력은 enc_outputs. 디코더로 전달하는 과정
enc_outputs=encoder(vocab_size=vocab_size,num_layers=num_layers,dff=dff,d_model=d_model,num_heads=num_heads,dropout=dropout)(inputs=[inputs,enc_padding_mask])
#디코더의 출력은 de_outputs, 출력층으로 전달하는 과정
dec_outputs=decoder(vocab_size=vocab_size,num_layers=num_layers,dff=dff,d_model=d_model,num_heads=num_heads,dropout=dropout)(inputs=[dec_inputs,enc_outputs,look_ahead_mask,dec_padding_mask])
#다음 단어 예측을 위한 출력층
outputs=tf.keras.layers.Dense(units=vocab_size,name='outputs')(dec_outputs)
return tf.keras.Model(inputs=[inputs,dec_inputs],outputs=outputs,name=name)
트랜스포머 하이퍼파라미터 정하기
앞선 과정까지는 전체 모델에 대한 이해와 이 모델을 직접 파이썬으로 구현하는 과정을 알아보았다.
이제는 학습을 시키기 위해 하이퍼파라미터를 지정해보자.
단어 집합의 크기는 임의로 9000으로 정한다. 단어 집합의 크기로부터 룩업 테이블을 수행할 임베딩 테이블과 포지셔널 인코딩 행렬의 행의 크기를 결정할 수 있다.
여기서는 논문에 제시한 것과는 조금 다르게 하이퍼파라미터를 정해본다. 인코더와 디코더의 층의 개수 num_laters는 4개, 인코더와 디코더의 포지션 와이즈 피드 포워드 신경망은 은닉층 d(ff) 128, d(model) 128, 멀티-헤드 어텐션은 병렬적 사용으로 num_heads 4로 지정해본다.
이렇게 된다면 d(v)는 128/4로 32가 되겠다
small_transformer=transformer(
vocab_size=9000,
num_layers=4,
dff=512,
d_model=128,
num_heads=4,
dropout=0.3,
name='small_transformer')
tf.keras.utils.plot_model(small_transformer,to_file='C:/data/small_transformer.png',show_shapes=True)
손실 함수 정의하기
다중 클래스 분류 issue를 해결할 것이므로, cross_entropy 를 loss_function으로 정의하겠다.
def loss_function(y_true,y_pred):
y_true=tf.reshape(y_true,shape=(-1,MAX_LENGTH-1))
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True,reduction='none')(y_true,y_pred)
mask=tf.cast(tf.not_equal(y_ture,0),tf.float32)
loss=tf.multiply(loss,mask)
return tf.reduce_mean(loss)
학습률
트랜스포머의 경우 learning rate는 고정된 값을 유지하는 것이 아닌, 학습 경과에 따라 변하도록 설계되었다.
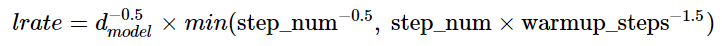
위 공식으로 학습률을 계산하여 사용하며, warmup_steps의 값으로는 4000을 정의하였다.
class CustomSchedule(tf.keras.optimizers.schedules.LearningRateSchedule):
def __init__(self,d_model,warmup_steps=4000):
super(CustomSchedule,self).__init__()
self.d_model=d_model
self.d_model=tf.cast(self.d_model,tf.float32)
self.warmup_steps=warmup_steps
def __call__(self,step):
arg1=tf.math.rsqrt(step)
arg2=step*(self.warmup_steps**-1.5)
return tf.math.rsqrt(self.d_model)*tf.math.minimum(arg1,arg2)
sample_learning_rate=CustomSchedule(d_model=128)
plt.plot(sample_learning_rate(tf.range(200000,dtype=tf.float32)))
plt.ylabel('Learning Rate')
plt.xlabel('Train Step')Text(0.5, 0, 'Train Step')

이후에는 이 트랜스포머 모델을 활용해 챗봇을 만들어 보겠다.
[출처]
'Deep Learning > NLP' 카테고리의 다른 글
| 01) 토큰화(Tokenization) (0) | 2021.03.10 |
|---|---|
| 트랜스포머(Transformer)(1) (0) | 2021.03.04 |
| Transfer Learning(전이 학습) (0) | 2021.03.02 |